
始めに
ユーザが対話型で指示(プロンプト)を与えて、文章を生成できる大規模言語モデルはAI分野において革新的な技術となった。2023年9月にはOpenAI社によりGPT-4Vがリリースされ、従来のChatGPTと画像を参照しながらユーザと対話することが可能となり、話題になった。
人間は知らず知らずのうちに、視覚、聴覚、嗅覚、味覚、触覚といった様々な感覚を使いこなし情報を高速に処理している。AGI(汎用的な人工知能)の構築には、これらの感覚を処理できるマルチモーダルな情報の理解性能の向上が不可欠である。本記事では、マルチモーダルな情報を処理するAIの中でも、視覚情報と言語情報を組み合わせたVision&Languageを対象にタスクや歴史を紹介する。そのうえで、本分野において利用可能なオープンモデルをいくつかご紹介したい。
Vision&Languageにおける代表的なタスク
従来型のコンピュータビジョン分野における代表的なタスクとしては、画像認識・物体検出・セグメンテーション・姿勢推定等が挙げられていた。AIブログ | 第5回:画像処理タスクにおけるディープラーニングモデルの活用で紹介したように、各タスクに特化したモデルが公開されている。
Vision&Languageにおけるタスクが、これらタスクと異なる点は画像情報と自然言語情報の異なる二つのモダリティの相互の関係性を学習する点にある。
近年、Transformerの登場により自然言語情報の意味空間をより正確なベクトル表現として表すことが可能になった。これにより、教師ラベルやモデルの入力として文章のような長いシーケンスを扱うことが可能になったことが、近年のVision&Languageの盛り上がりの1つの要因と言えるだろう。

出所:三菱総合研究所
以下、Vision&Languageにおいて有名なタスクをいくつかご紹介させていただく。
- ①画像・動画生成
与えられた文章に対して適切な画像を生成する。詳細な説明はAIブログ | 第5回:画像処理タスクにおけるディープラーニングモデルの活用にて紹介があるため、割愛する。最近では、画像生成を更に発展させた動画生成が盛り上がりを見せている。2024年3月にOpenAIが発表したSoraでは最長1分の動画を与えられた文章から生成する。今後、更に高精度・長時間の生成を可能とするモデルの構築に向けた研究が加速すると予想する。
- ②VQA
画像情報を元に与えられた質問に対して回答するタスクである。例えば、犬が食事している写真に対して「What’s the dog doing?」という質問に「eating」という回答を返すようなタスクである。
【図:VQAの例】 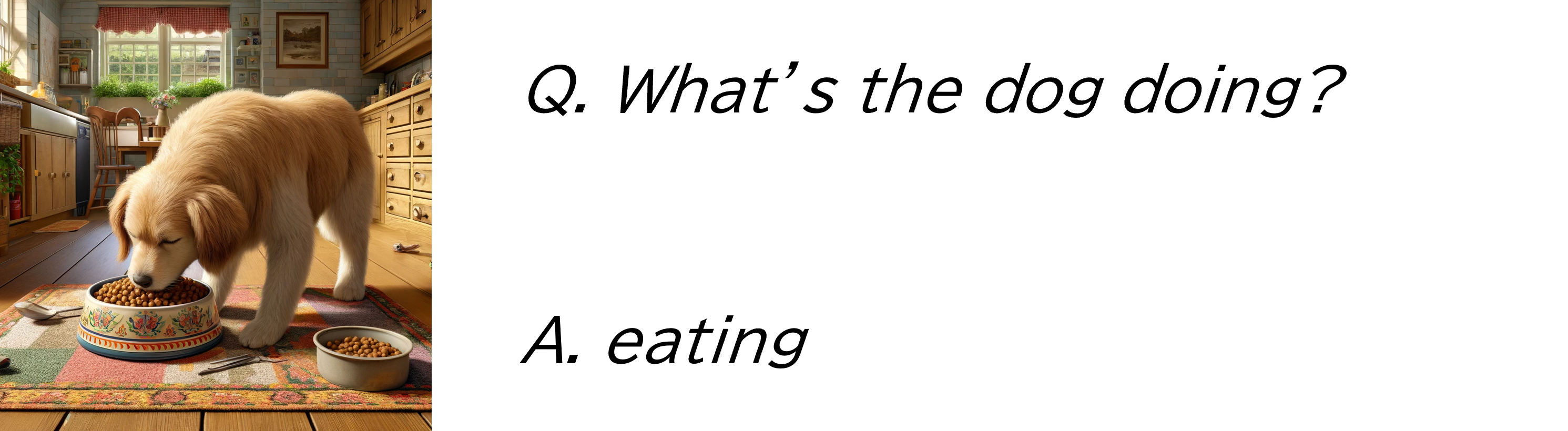
出所:三菱総合研究所, 画像はChatGPT(OpenAI.)により生成
- ③Image Captioning
特定の画像に対して適切な説明文を付与するタスクである。このタスクではより正確に与えられた画像が持つ特徴を説明することが求められる。例えば、以下のような夜景とビールグラスが並ぶ画像に対して適切な状況を説明するといったタスクである。
【図:Image Captioningの例】 
出所:三菱総合研究所, 画像はChatGPT(OpenAI.)により生成
- ④テキストプロンプトによるセグメンテーション/物体検出
一般的な従来のコンピュータビジョンのタスクに対しても言語情報を適用可能にする(一般的にVisual Groundingと呼ぶ)ような研究も非常に進んでいる。例えば、下の図のピンク色の領域のように、画像に対して文章が示す領域を検出・分離することを可能とするタスクである。
【図:Visual Groundingの例】 
出所:三菱総合研究所, 画像はChatGPT(OpenAI.)により生成
CNN登場以降~Vision&Language発展までの歩み
本節ではCNN登場以降のコンピュータビジョンを振り返るともに、Vision&Language発展までの動向を説明する。下の図は2012年から2024年までのVision&Languageに関係するモデルの発展を示している。
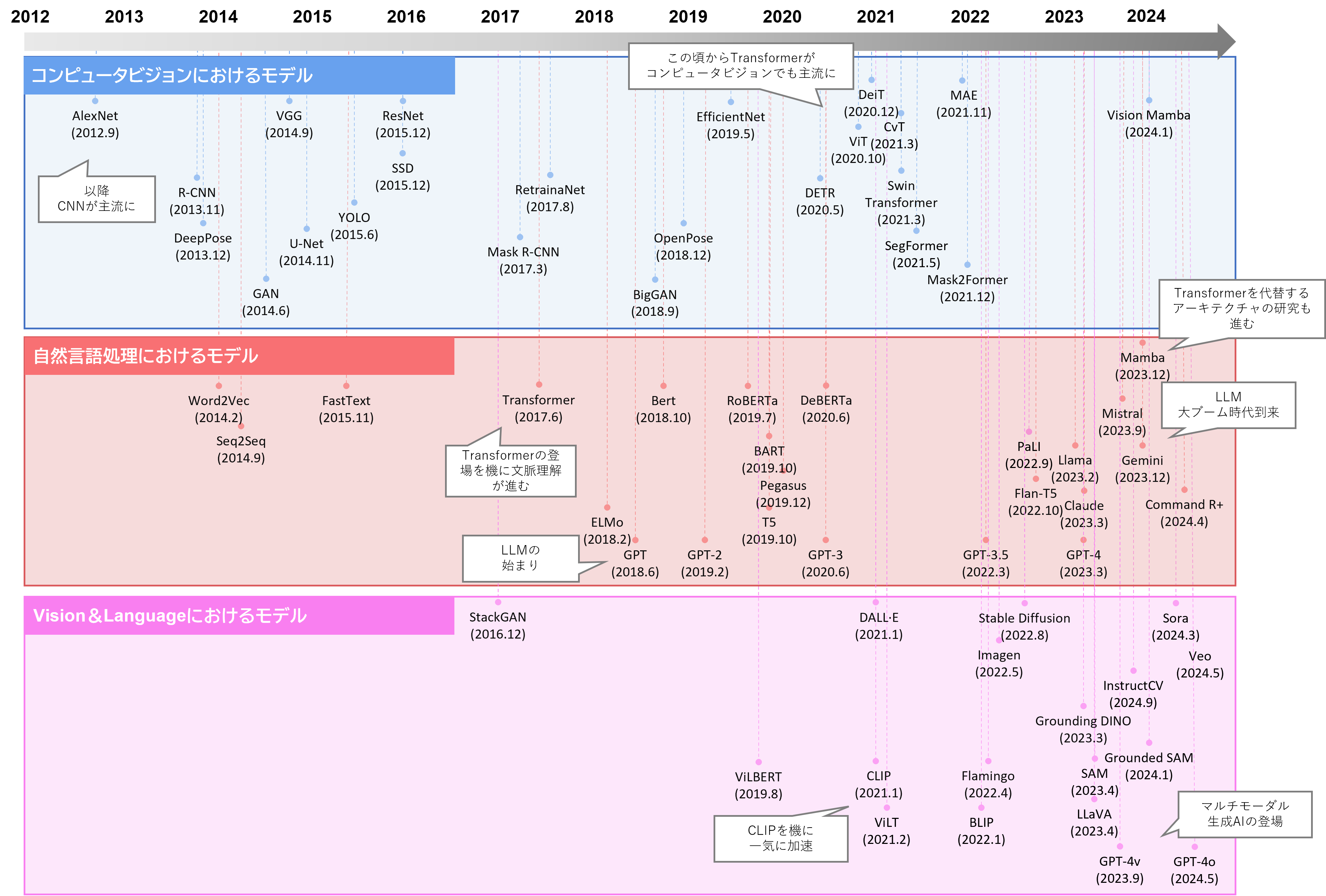
出所:三菱総合研究所
コンピュータビジョンの分野において、Transformer登場以前はCNNを用いることが一般的であった。CNNは、入力画像を畳み込み層やプーリング層などの層に通すことにより、特徴量を抽出し、画像分類や物体検出などのタスクを行うニューラルネットワークの一種である。CNNは1980年代から近いアーキテクチャであるLeNetが提案されていたが、その可能性が広く認知されたのは2012年のImageNet Large Scale Visual Recognition Challenge(ILSVRC)である。このコンペティションでは、AlexNetと呼ばれる8層のCNNが従来の手法を大きく上回る精度を達成し衝撃を与えた。
AlexNetの成功以降、CNNの層数やアーキテクチャを工夫することで、さらに高い性能を目指す研究が盛んになった。例えば、2014年にはVGGといった16層以上の深いCNNが登場した。また、2015年にはResNetと呼ばれる残差接続(Skipp-Connection)を用いたCNNが発表され、CNNの課題であった勾配消失を解決し、より大規模なパラメータのモデル構築を可能とした。このアーキテクチャはTransformerや近年の生成AIモデルでも導入される重要なアーキテクチャとなっている。
CNNは画像分類だけでなく、物体検出(SSD, YOLO)やセグメンテーション(Masked- R-CNN, U-net)といったタスクにも応用された。以降、コンピュータビジョンのスタンダードとして使用される。
自然言語処理の分野では、2017年にGoogleがAttention is All You Need(https://arxiv.org/pdf/1706.03762)という論文を発表し、自然言語処理の分野に大きな革命が起こった。この論文ではTransformerという新たなアーキテクチャが提案された。
Transformerは、アテンション機構というアーキテクチャのみで構築された自然言語処理モデルであった。アテンション機構とは、入力系列の各要素に対して重み付けを行い、関連性の高い要素に注目することで、出力系列の各要素を生成するアーキテクチャである。Transformerは自然言語の分野でさらに発展し、BERTやGPTなどにも利用され、自然言語処理の分野の新たなスタンダードとなった。
Transformerは自然言語処理の分野で大きな成功を収めたが、コンピュータビジョンの分野にも応用されるようになった。2020年に登場したVision Transformer(以下、ViT)は最も有名な画像分野における応用である。大規模なデータセットを訓練させたViTは既存のCNNの性能を上回ることを証明した。ViTは画像を小さなパッチ単位に分割し、それらを一次元の系列として扱うことでアテンション機構によりに画像を処理することを可能とした。
CNNは局所特徴の理解に強く、離れた位置にあるピクセル間の理解が難しいという課題があった。人は部分的なテクスチャを見て物体を判断するのではなく、全体的な形状を見て物体を認識する場合が多い。以下の論文(https://arxiv.org/abs/2105.07197)ではCNNとViTの視覚認識の特性についてそれぞれ検証を行っている。
ViTは大域的な特徴に対して理解に強く、全体の形状を見て認識を行うため、より人間の視覚に近い画像理解を可能にすることが検証により明らかとなった。また、以下の論文(https://ar5iv.labs.arxiv.org/html/2108.13002v1)ではTransformer, CNN, MLP構造の比較検証が行われた。この論文ではTransformerとCNNのハイブリッドモデルが有効であることも示している。
結果として、Transformerは自然言語とコンピュータビジョン、どちらに対しても大きな影響を与える結果となった。
しかし、画像と自然言語という異なる種類のデータの相互の関係性を統合的に理解することはTransformerの登場のみでは解決困難な課題であった。2021年にOpenAIよりCLIP(Contrastive Language-Image Pre-training)というモデルが発表された。CLIPは高いゼロショット性能を保持しており、画像情報と自然言語情報を共潜在空間へと射影することを可能にした。CLIPの学習は下の図に示すように文章エンコーダと画像エンコーダを用いて行われる。
N個の画像とテキストのペアのバッチが与えられると、それぞれのエンコーダは画像ベクトル表現Iと文章ベクトル表現Tへと変換する。正しいペアのコサイン類似度を算出し最大化し、間違っているペアのコサイン類似度は最小化する。CLIPはインターネット上より収集された4億以上ものペアを用いて学習されており、画像エンコーダにViTとResNetを利用したモデルがそれぞれ公開されている。
CLIPは多くのVision & Languageのモデル研究における基盤となっている。HuggingFace(AIモデルやデータを共有利用するためのオープンソースプラットフォーム)における2024年4月のダウンロード数が1000万回を超えていることからもその影響力が図り知れないことが分かるだろう。CLIPは画像生成AIであるStable DiffusionやマルチモーダルLLMのLLaVAなどに応用されている。CLIPは近年の生成AIの発展にとって欠かせない存在となった。
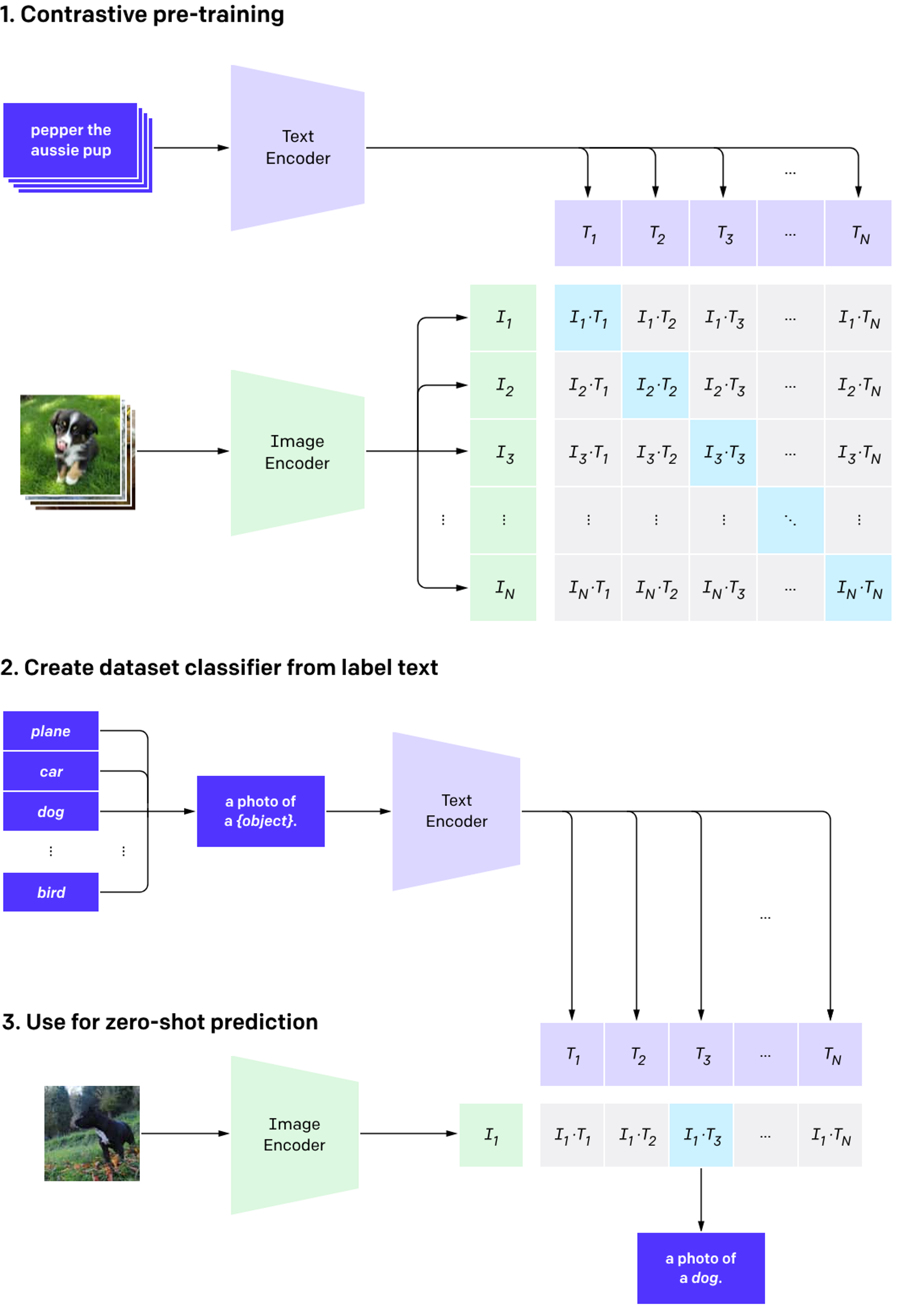
出所:“Learning Transferable Visual Models From Natural Language Supervision” Figure 1.より引用
https://arxiv.org/pdf/2103.00020
Vision&Languageの代表的なオープンモデルの紹介
以下、Vision&Languageにおけるオープンソースで利用可能なVision&Languageにおけるモデルを紹介する。
- ①Stable-Diffusion-XL, Stability AI / 画像生成
Stable Diffusionはプロンプトに応じて画像を生成可能なモデルである。Stable Diffusionは様々なモデルが公開されているが、公開中のモデルで最も高品質な画像の生成が可能なのがStable-Diffusion-XLである。
Stable-Diffusion-XLを軽量化し、高速化したモデルSDXL-turboや日本語対応に特化したモデルJapanese Stable Diffusion XLも公開されている。ライセンスはCreativeML Open RAIL++-M Licenseである。
【図:Stable-Diffusion-XLが生成した画像例】 
出所:“SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis” Figure 1.より引用
https://arxiv.org/pdf/2307.01952 - ②Open-Sora, HPC-AI Tec / 動画生成
Open-Soraでは一般ユーザに未公開のSoraの再現実装を行っており、誰もがそのモデル、ツール、コンテンツを利用可能にすることを目的としている。現時点ではまだ初期段階にあり、更に高品質・長時間の生成が可能になると考えられる。現時点では、2~15秒の動画の生成・144p~720pの解像度の動画を生成することが可能である。ライセンスはApache 2.0 licenseである。
- ③BLIP-2, Salesforce / Image Captioning&VQA
BLIP-2はImage CaptioningやVQAのタスクにおいて有名なモデルである。
BLIP-2ではCLIPに近いアーキテクチャの事前学習済みの画像エンコーダと事前学習済みの大規模言語モデルを利用して、様々なVision&Languageタスクを実施することが可能なモデルである。BLIP-2では画像エンコーダと大規模言語モデルの重みを固定し、二つを結合するパラメータ数の少ないQ-Former部分のみを更新する。低パラメータ数の更新で良いにも関わらず、当時のSOTA(state-of-the-art)を達成したことで話題を集めた。ライセンスはMIT Licenseである。
【図:BLIP-2のアーキテクチャ】 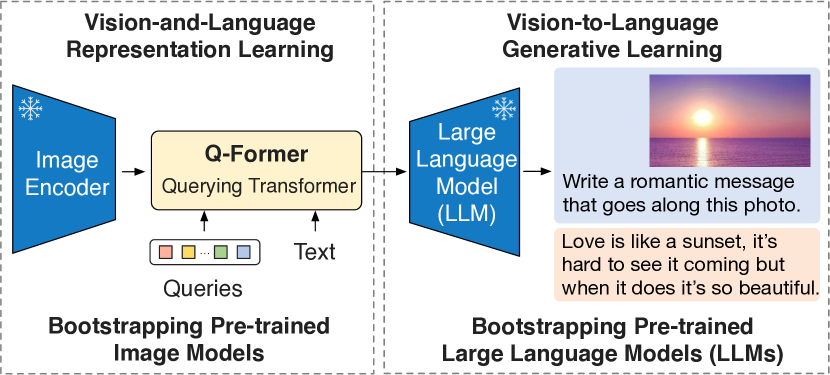
出所:“BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models” より引用
https://arxiv.org/pdf/2301.12597 - ④Grounded SAM, IDEA-Research / テキストプロンプトによるセグメンテーション
Grounded SAMは従来のセグメンテーションタスクを任意のテキストに基づいて実施することを可能としたモデルである。Grounded SAMは、ポイントやボックスとして与えた任意の指示に対してセグメンテーションを可能としたモデルであるSAMをテキスト入力による指示でも分離可能なモデルとして応用した。Grounded SAMは様々なコンピュータビジョンタスクに組み込むことで、より複雑なタスクを解くことを可能とする。例えば、Stable DiffusionとGrounded SAMを組み合わせることで 高精度に部分的な画像編集を実行することが可能である。ライセンスはApache 2.0 licenseである。
【図:Grounded SAMによるテキストを用いたセグメンテーションの例】 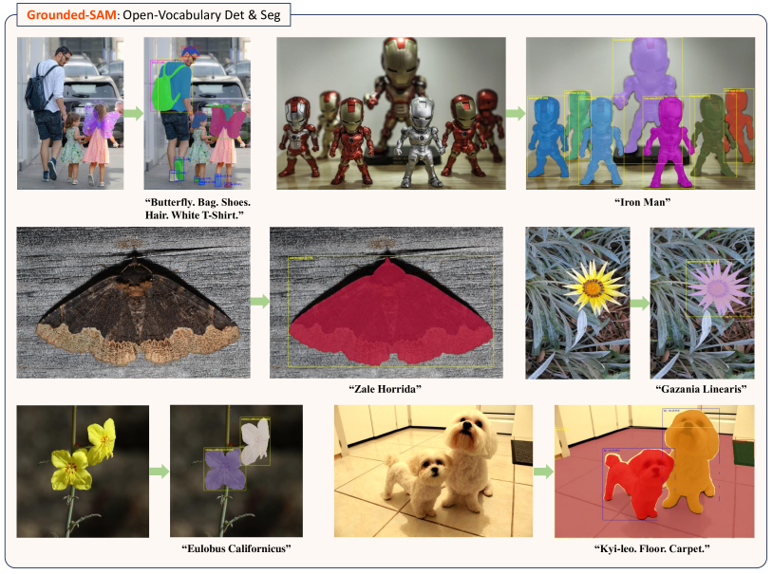
出所:“Grounded SAM: Assembling Open-World Models for Diverse Visual Tasks” Figure 2より引用
https://arxiv.org/pdf/2401.14159
Vision&Languageのビジネスにおける応用事例
本セクションでは日本国内において、Vision&Languageが活用されている事例をピックアップして紹介したい。
- ①自動運転産業における活用事例
株式会社Turingはカメラ画像からEnd to End(E2E)で直接運転指示を行う高度な自動運転AIの開発に取り組む。Vision&Language技術を活用し、交通標識や道路上の指示を視覚情報から読み取り、自然言語処理を通じてこれを車両の行動指針に変換する。車両が人間のドライバーと同様に、複雑な交通状況を理解し適切に反応することを可能とする。また、運転中の一瞬の判断を可能とするため、モデルの圧縮や車載ハードウェアへの最適化などの技術によってリアルタイム性と計算効率の向上にも取り組んでいる。
Turing、完全自動運転EV「2030年10,000台」宣言 半導体チップも製造へ | 自動運転ラボ (jidounten-lab.com)
- ②広告業・マーケティングにおける活用事例
株式会社サイバーエージェントは生成AIを活用した商品画像の自動生成に取り組む。従来、広告商品を撮影するには様々な機材やセット、ロケーションが必要であったが、背景を自動生成することでこれらの手間を削減した。また、商品画像そのものを学習に組み込むことで、より自然な商品画像の生成や光彩など複雑な表現にも対応している。高速な生成が可能な本技術を、広告の効果予測技術や従来のAIと組み合わせ、より広告効果の高い商品画像の制作を実現している。
極予測AI、生成AIを活用した商品画像の自動生成機能を開発・運用開始へ | 株式会社サイバーエージェント (cyberagent.co.jp)
- ③ロボット制御における活用事例
オムロンの子会社であるオムロンサイニックエックス株式会社は、自動調理ロボットの実現に向けてVision&Language技術を活用している。具体的には、料理ロボットを動かすために必要な料理マニュアルの自動生成を行い、料理ロボットを動かすための要素技術として扱う。本事例のように今後ロボティクス×マルチモーダルな生成AIの活用がより盛り上がりを見せるだろうと筆者は予測する。
オムロン傘下の研究開発機関、言語指示で動くロボットなどの研究状況を公開 | 日経クロステック(xTECH) (nikkei.com)
まとめ
本記事では、Vision&Language分野のタスク、歴史的経緯、モデル、応用事例を紹介した。Vision&Languageに関わらずマルチモーダルな情報を処理するAI技術は今後更に発展し、ロボティクス分野との連携が加速していくだろう。コンピュータビジョンのトップカンファレンスであるCVPR2024において、Embodied AIを対象としたワークショップが開催されていることからも、その注目度の高さは明らかである。
今回ご紹介した分野では、新たなモデルが頻繁に登場し続けるため、いかにビジネスに対する影響があるか考え続けることが重要である。新たなモデルが登場し利用する際はライセンスに留意しつつ、個別の業務やユースケースに合わせた評価用データを整備し、ベンチマークを行うことが重要である。まずはビジネスにおいて、どのような評価が好ましいのか、検証に必要なデータはどのように取得できるかを考え、一連のプロセスを見直してみることから始めるとよいだろう。
筆者



DXメルマガ
配信中

関連サービス・
ソリューション



プロダクト
マネージャー募集中
