
2023.7.7
武田 智博
2022年11月に登場したChatGPTに代表されるように自然言語分野におけるAIの発展はめざましいが、画像処理分野におけるAI活用もまた例外ではない。例えば、以前は実用観点では難のあった画像生成分野では、第1回でも紹介したStable Diffusionの登場により高品質な画像を生成できるようになった。ここでは、代表的な画像処理タスクを整理し、これらのタスクに適用可能なオープンなモデルおよびデータセットを紹介する。
なお、本記事ではソースコード本体のライセンスについてのみ言及しており、学習済みモデル(重み)については多様なライセンスで提供されているため、個別に確認が必要な点は留意されたい。
なお、本記事ではソースコード本体のライセンスについてのみ言及しており、学習済みモデル(重み)については多様なライセンスで提供されているため、個別に確認が必要な点は留意されたい。
代表的な画像処理タスク
① 物体検出(Object Detection)
物体検出は、人が目で物を見て認識するように、入力された画像に対して「どこに」「何が」あるかを検出するタスクである。画像処理分野で最も良く行われているタスクである。一般には、画像内に存在する複数の物体を矩形単位(バウンディングボックス、BBoxという)で位置を特定し、同時にどのクラス(カテゴリ)に属するのかを分類する。車、猫といったカテゴリに分類する類別タスクと、車種や猫の種類を特定する識別タスクに大別される。

出所:株式会社 三菱総合研究所
② セグメンテーション(Segmentation)
セグメンテーションは物体検出タスクのひとつであるが、矩形単位ではなくピクセル単位で行う点が異なる。同じカテゴリの物をひとまとまりにして区別しないセマンティックセグメンテーション、同じカテゴリであっても一つ一つ物体を区別して検出するインスタンスセグメンテーション、ピクセル単位でカテゴリ分類しつつ物体を個別に検出するパノプティックセグメンテーションなどがある。
セマンティックセグメンテーションは全ての領域を何らかのクラスに分類することが得意である。対して、インスタンスセグメンテーションは個別の物体を検出することはできるが、境界が曖昧な雲、空といった背景などを認識することが難しい。パノプティックセグメンテーションは、両セグメンテーションの特性を備えており、物体を検出しつつ、境界が曖昧な領域についても何らかのクラスに割り当てることができる。
セマンティックセグメンテーションは全ての領域を何らかのクラスに分類することが得意である。対して、インスタンスセグメンテーションは個別の物体を検出することはできるが、境界が曖昧な雲、空といった背景などを認識することが難しい。パノプティックセグメンテーションは、両セグメンテーションの特性を備えており、物体を検出しつつ、境界が曖昧な領域についても何らかのクラスに割り当てることができる。

出所:株式会社 三菱総合研究所

出所:株式会社 三菱総合研究所
③ 画像分類(Image Classification)
入力された画像に「何が存在するか」を判断する目的で、画像全体からどのクラス(カテゴリ)に属するのかを分類するタスクである。例えば、手書き文字の認識では1文字1文字をクラス分類することで認識することが可能である。位置を特定するケースもあるが物体検出と異なり、画像を分類することが目的である。さらに、自然言語モデルと組み合わせることにより画像に何が描かれているかを説明する、画像キャプション生成(Image Captioning)タスクがある。
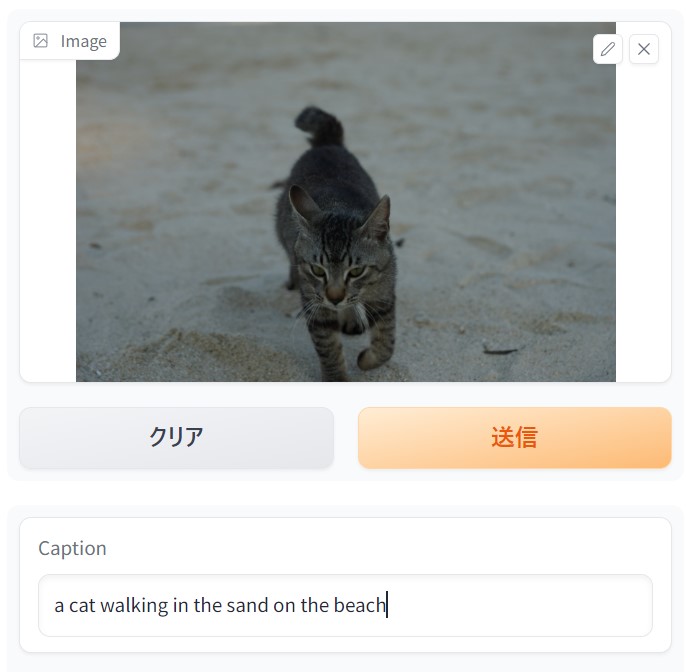
出所:株式会社 三菱総合研究所
④ 異常検知(Anomaly Detection)
異常検知は画像に限ったタスクではないが、定常状態を学習させることにより、そこから外れるものを異常として検知する手法である。正常の定義が可能で、異常の教師数が極端に少なく、異常を異常として学習させることが難しい場合に主に採用される。

出所:株式会社 三菱総合研究所
⑤ 画像生成(Image Generation)
指示に基づき、任意の画像を生成するタスクである。Stable Diffusionの登場により一般に広く知られるようになった。プロンプトと呼ばれるテキストから画像を生成するケース、元となる画像とプロンプトから画像を生成するケース(例えば線画への彩色タスク)が挙げられる。

出所:株式会社 三菱総合研究所
これらの代表的なタスク以外にも、動画像における行動検出といったタスクも存在する。
代表的なオープンモデル
(参考)
(参考)
(参考)
AEはシンプルなモデルであり、Tensorflow, PyTorch, Caffeといったディープラーニングライブラリを用いて実装することが多いため、参考リンクは割愛する。
(参考)
ビジネス課題でのアプローチ例
例1)製品検査における不良品の検知
すでに多くの工場や製造ラインで活用されているアプローチ例ではあるが、不良品はサンプル数が少なく、不良品そのものを学習させることが困難なケースが多い。このため、異常検知タスクが用いられるケースがある。画像生成を用いて検知することも今後は考えられる。
すでに多くの工場や製造ラインで活用されているアプローチ例ではあるが、不良品はサンプル数が少なく、不良品そのものを学習させることが困難なケースが多い。このため、異常検知タスクが用いられるケースがある。画像生成を用いて検知することも今後は考えられる。

ネジ不良品のイメージ
例2)セグメンテーションを用いたリアルタイムカメラ映像処理
自動運転においては画像のみに頼らずLiDARのようなセンサーも必要となるが、ドライブレコーダーのように車載カメラでの用途が考えられる。車載カメラの場合は、危険を検知する目的が一般的なため、物体を区別するインスタンスセグメンテーションよりは、より単純なセマンティックセグメンテーションでリアルタイム性を重視するケースなどが考えられる。
自動運転においては画像のみに頼らずLiDARのようなセンサーも必要となるが、ドライブレコーダーのように車載カメラでの用途が考えられる。車載カメラの場合は、危険を検知する目的が一般的なため、物体を区別するインスタンスセグメンテーションよりは、より単純なセマンティックセグメンテーションでリアルタイム性を重視するケースなどが考えられる。

車載カメラのイメージ
例3)ゲームにおける背景画像の自動生成
ゲームシナリオのプロットを広げるためにChatGPTとの対話を活用するように、必要不可欠ではあるがそれほど重要ではない場所において画像生成を活用することで効率化を図ることができる。初期のプロトタイプ段階において生成画像を用いて何パターンか試すことでイメージを掴む目的でも利用可能である。
ゲームシナリオのプロットを広げるためにChatGPTとの対話を活用するように、必要不可欠ではあるがそれほど重要ではない場所において画像生成を活用することで効率化を図ることができる。初期のプロトタイプ段階において生成画像を用いて何パターンか試すことでイメージを掴む目的でも利用可能である。

ゲーム背景のイメージ
代表的なオープンデータセット
最後に、ここまでに紹介したオープンなモデルの学習にも使われており、広く知られているオープンなデータセットを紹介する。以下に挙げるオープンデータセットは数千から数十万の画像およびアノテーションを含んでおり、多くは研究および教育用途に公的に利用することができる。商用利用の際には各データセットのライセンスおよび利用規約を参照いただきたい。
- COCO
- ImageNet
- PASCAL VOC
- Open Images dataset
合成データセットの事例として、ここではRare Planesを紹介する。衛星画像のように撮影が容易ではなく、数を確保することが難しいタスクにおいては、合成データセットを活用する場合がある。
オープンなデータセットは日々作成されており、ここで紹介したものはほんの一部に過ぎない。前述の画像生成モデルを用いてデータセットを生成する活用も始まっている。
オープンなデータセットは日々作成されており、ここで紹介したものはほんの一部に過ぎない。前述の画像生成モデルを用いてデータセットを生成する活用も始まっている。

出所:”RarePlanes: Synthetic Data Takes Flight“ Figure 1.より引用
https://arxiv.org/abs/2006.02963
https://arxiv.org/abs/2006.02963
(参考)
まとめ
典型的な画像処理タスクとそれらに対応する代表的なオープンなモデル並びにデータセットを紹介した。深層学習は日進月歩のため、常に最新のモデルが登場し続ける状況ではあるが、モデルを最新化しつづけることよりもデータの量と質を上げる方が性能に寄与する場合も十分にある点は留意されたい。また、実際の利用に際してはライセンスを確認し、用途に合わせて適切なモデルを採用する必要がある。学習や推論を動かす際にベンチマークとなるデータセットがあると評価などが行いやすいため、普段から使えるオープンなデータセットを用意しておきたい。
次回は、画像生成により教師画像を生成した場合に物体検出タスクの精度への影響について記載する。
次回は、画像生成により教師画像を生成した場合に物体検出タスクの精度への影響について記載する。
筆者



DXメルマガ
配信中

関連サービス・
ソリューション



プロダクト
マネージャー募集中
