
2022年11月にChatGPTが発表されて以降、自然言語処理への注目が集まっている。ChatGPTは大規模言語モデル(以降LLM)を利用しており人間からの指示のみで様々な処理を行う事が可能である。本記事でもLLMに触れながらオープンなモデルを紹介したい。
自然言語処理で取り扱う問題
自然言語処理では様々な問題を様々な条件で扱っており、それらをタスクと呼んでいる。
| タスク名 | 概要 | ビジネス利用の例 |
|---|---|---|
| 分類 (Classification) |
あるテキストを様々なクラスに分類する。 | 大量のビジネス文書から重要なものと重要でないものを分ける。 |
| 質問応答 (Question Answering) |
あるテキストに対する質問に回答する。 | ビジネス文書と「作成日はいつですか?」という質問を用いて日付を抽出するなど、特定の記載を抜き出す。 |
| 機械翻訳 (Machine Translation) |
あるテキストを異なる言語に翻訳する。 | 英語で書かれた文書を日本語に翻訳する。 |
| 機械要約 (Summarization) |
あるテキストを要約し短い文書にする。 | 長いニュース記事から3行程度の要約を作成する。 |
| ベクトル化、分散表現 (Embedding) |
あるテキストの意味を表すベクトルを求める。 | 大量のテキストから探したいものに近い意味のテキストを見つける。 |
本記事では分類と質問応答タスクについて詳細に扱う。機械翻訳や要約など出力としてテキストを返すタスクは生成系タスクとも呼ばれる。生成系タスクとベクトル化は次回以降に取り扱う。
分類は自然言語処理において最も頻繁に利用されるタスクであり、ある文書を複数のカテゴリに分類する処理を指す。重要な文書であるか無いかのような判定や書かれた文書の分野(科学技術分野、金融分野など)の判定に用いる。
例えば次のような利用方法がある。
分類は自然言語処理の中でも良く用いられるものであり、上手く利用すると業務負荷を大幅に軽減できる。
質問応答は長い文章と人間からの質問から回答を作成するタスクであり、チャットボット等で利用されている。
例えば次のような利用方法がある。
分類、質問応答タスクの設定・解き方には様々なものがあるが、ここでは入力されたテキストに対して数値など決まった形式で出力を返すものを想定する。分類タスクであればそれぞれのカテゴリに入る可能性を表す数値、質問応答タスクでは回答の始点と終点を表す数値などである。
問題の解き方と特徴
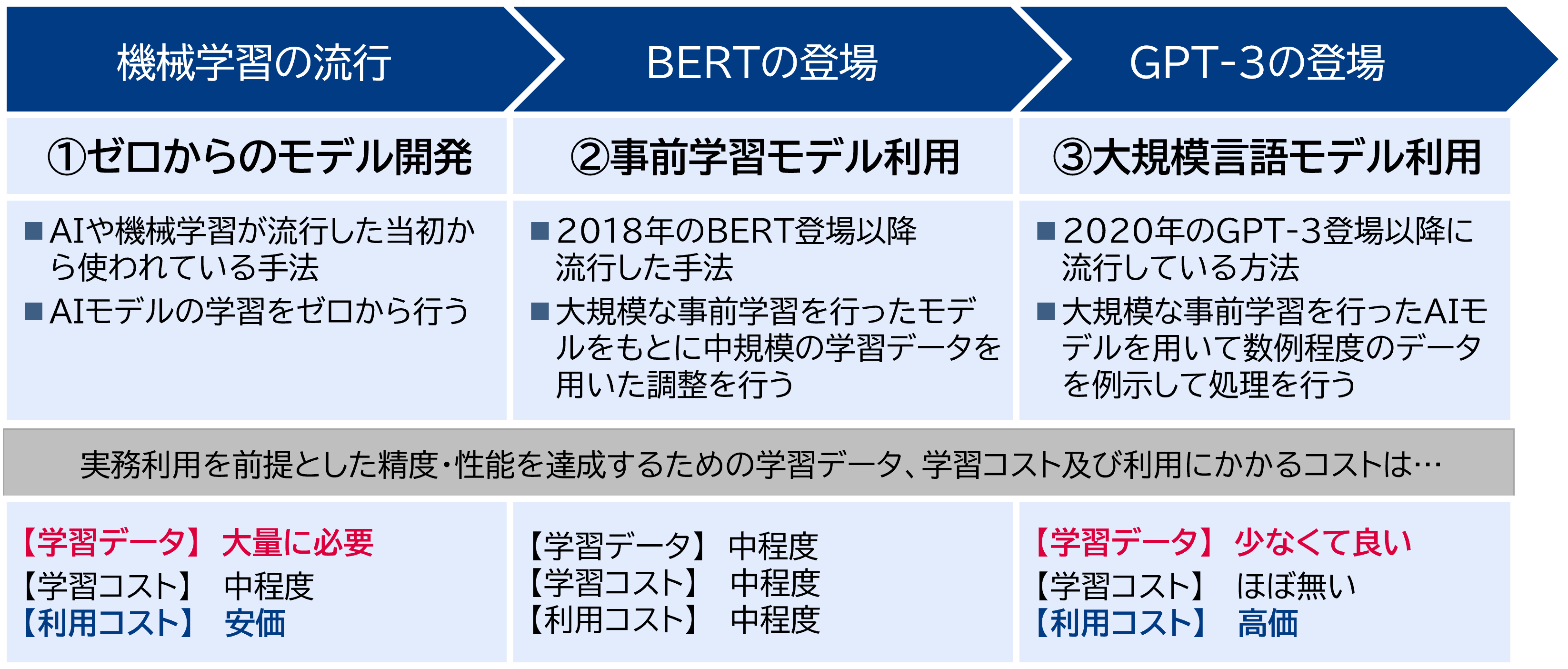
前述の通り自然言語処理の手法は年々発展しており、2018年のBERT、2020年のGPT-3、2023年のGPT-4など新技術が発表されている。現時点では①ゼロからのモデル構築、②事前学習モデルを用いたモデル構築、③大規模言語モデルを利用の3つが有力である。最近では③の大規模言語モデルを活用する方針の採用が多くなっている。大掛かりなデータセットが不要で短いサイクルでの試行が可能という利点があるが、実運用時のコストが高く処理性能を上げにくいなど課題も多いためユースケースに合わせた選択が重要である。
出所:三菱総合研究所
-
① ゼロからのモデル開発
大量の教師データを作成し、ゼロからGBMやLSTMなどの手法によってAIモデルを構築する。
教師データ作成の負荷が高い一方でモデルを利用するコストが安い。 -
② 事前学習モデルを用いた開発
「中規模の教師データ」と「大規模データで事前学習を行った事前学習済みモデル」を用いてAIモデルを構築する。「事前学習モデルをFine tuningする」と表現することもある。教師データ作成の負荷は中程度、モデルを利用するコストも中程度となる。
事前学習済みモデルとしてオープンなモデルが公開されている。それらを活用することで効率的にAIモデルの開発が可能である。 - ③ 大規模言語モデルを用いた開発 教師データをほとんど作成せず、数例程度のサンプルデータと指示によってAIモデルを動作させる。APIを通してLLMを用いる方針と②と同じようにオープンなモデルを活用し自社内で運用する方針がある。前者の場合、教師データ作成の手間が無い一方でモデル利用に関わるコストはAPI利用料に依存する。大量のモデル利用をする場合は利用料が①、②よりも高額になる可能性がある。後者の場合②に近い開発となる。モデル規模が大きいためモデル利用にはより多くの計算リソースが必要となる。
ビジネス利用においては必ずしも最高性能を目指す必要はなく、合理的な性能を目指せばよいため、必ずしも新しい技術が優れているわけではない。データ量とモデル利用の頻度、AI構築にかけられる時間によって利用すべき手法が変化する。
ChatGPT内で使われているGPT-3.5やGPT-4は③の方針として活用することができ性能も高い。タスクにもよるが少量のデータで②の方針と同等の性能を出すことが可能な場合もある(後述)。モデル利用の回数が少ない場合やプロトタイプ開発など短期間でAI活用をする場合は有力な選択肢になる。
モデル利用の回数が多い場合や教師データが十分にある場合、セキュリティ等の都合で外部にデータを送信できない場合は①②の選択肢が有力となる。
分類・質問応答におけるオープンなモデル
分類・質問応答は前述「②事前学習モデルを用いた開発」のアプローチ、BERT及びその後継モデルを利用して効果的に解くことが可能である。分類・質問応答以外のタスクについては事情が異なるため次回取り扱う。
日本語を扱う場合は日本語専用の事前学習モデルを使うか多言語対応した事前学習モデルを用いる必要がある。BERTについてはそれぞれの方針で構築したオープンな事前学習モデルが存在する。
日本語専用のBERTやその後継モデルの例
- NICT BERT 日本語 Pre-trained モデル
- 情報通信研究機構 データ駆動知能システム研究センターによる事前学習済みモデル
- ライセンスはCreative Commons — 表示 4.0 国際 — CC BY 4.0
- RoBERTa日本語Pretrainedモデル
- 早稲田大学 基幹理工学部 情報通信学科 河原研究室による事前学習済みモデル
- ライセンスはCreative Commons — 表示 - 継承 4.0 国際 — CC BY-SA 4.0
- LUKE Japanese
- 株式会社Studio Ousiaによる事前学習済みモデル
- ライセンスはApache-2.0
多言語対応かつ日本語を扱えるBERTやその後継モデルの例
- mBERT (multilinbual BERT)
- HuggingFace社が公開しているmBERTの事前学習済みモデル
- ライセンスはApache-2.0
- mT5 (multilingual T5)
- Google社によるmT5の事前学習済みモデル
- ライセンスはApache-2.0
最近では前述「③大規模言語モデルを用いた開発」に使用可能なオープンな大規模言語モデルも公開されている。大規模言語モデルでも日本語を扱う場合は日本語専用または日英対応の事前学習モデルを使うか多言語対応の事前学習モデルを用いる必要がある。日本語に対応したLLMの開発も非常に活発であり、その評価はStability AI社のJP Language Model Evaluation HarnessやNejumi LLMリーダーボードが参考になる。
公開されている大規模言語モデルのライセンスは様々である。例えばLlama-2は商用利用可能だが一定の制約があり、数多く公開されている派生モデルでも同様の制約がある。利用時にはライセンス文書を確認いただきたい。
比較的利用がしやすいApache-2で公開されているモデルを例示するが、「チューニング済みモデルは商用利用不可」などバリエーションによって利用条件が異なることがある点に注意が必要である。
日本語を扱えるLLMの例
- LLM-jp-13B
- 大学共同利用機関法人 情報・システム研究機構 国立情報学研究所が主催するLLM勉強会で構築された日本語対応LLM
- ライセンスはApache-2.0
- PLaMo-13B
- Preferred Networks社によって構築された日本語対応LLM
- ライセンスはApache-2.0
- Japanese Stable LM Gamma 7B
- Stability AI Japan社がMistral AI社のMistral-7B-v0.1を元に開発したLLM。
- ライセンスはApache-2.0
自然言語処理をビジネスに活用する場合の進め方と注意点
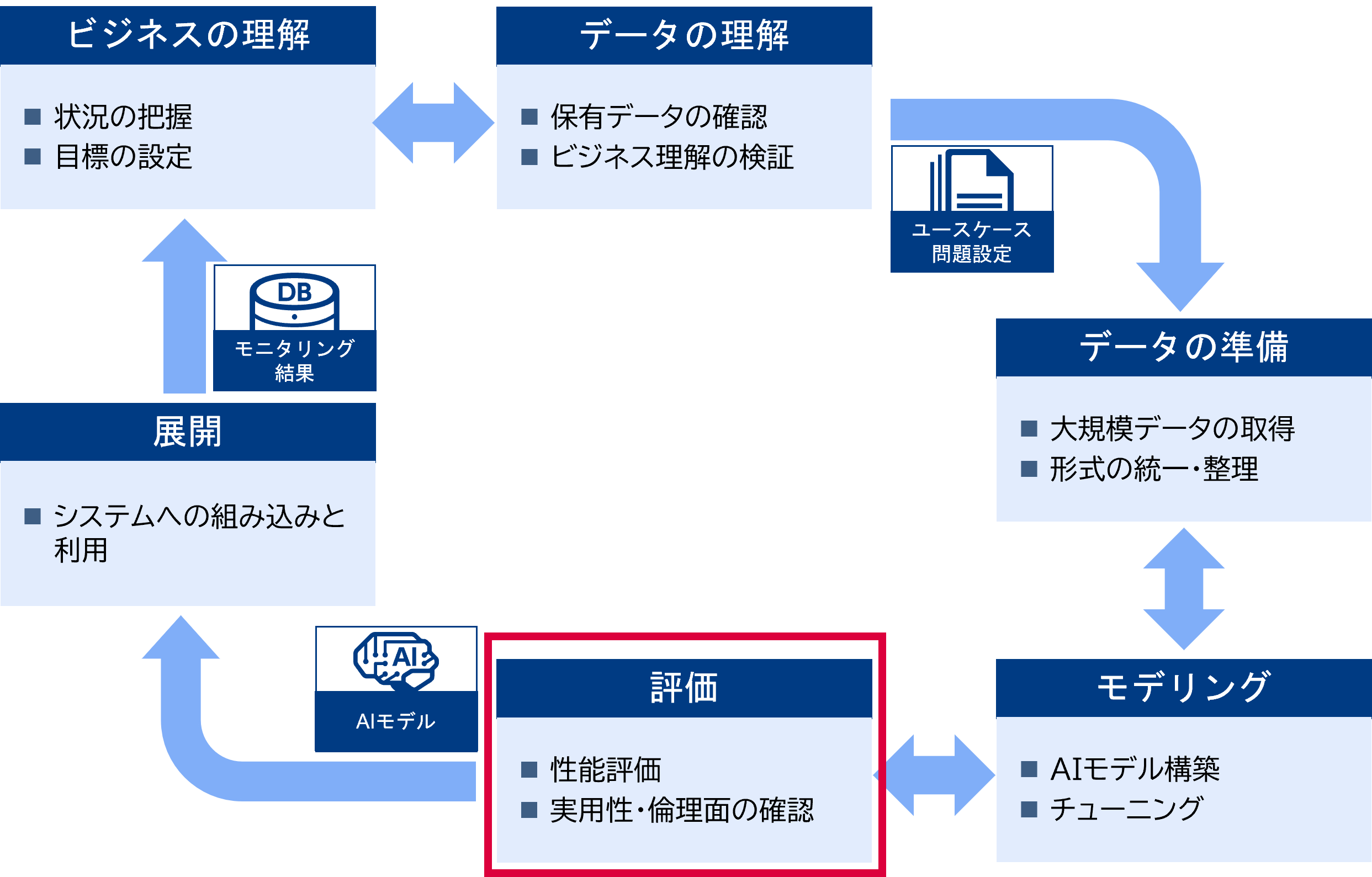
下図は大規模言語モデルを使用する場合と使用しない場合のAIモデル構築のフローである。大規模言語モデルを利用する場合は大規模なデータ構築が不要でユースケースや解くべき問題を整理しながらAI開発の試行ができる。小規模な問題であれば最後まで大規模データの準備やモデリングが不要なこともある。今までのAI開発よりも短いサイクルで成果を出すことができ、アジャイルなソフトウェア開発手法との親和性も高い。
https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining
出所:三菱総合研究所
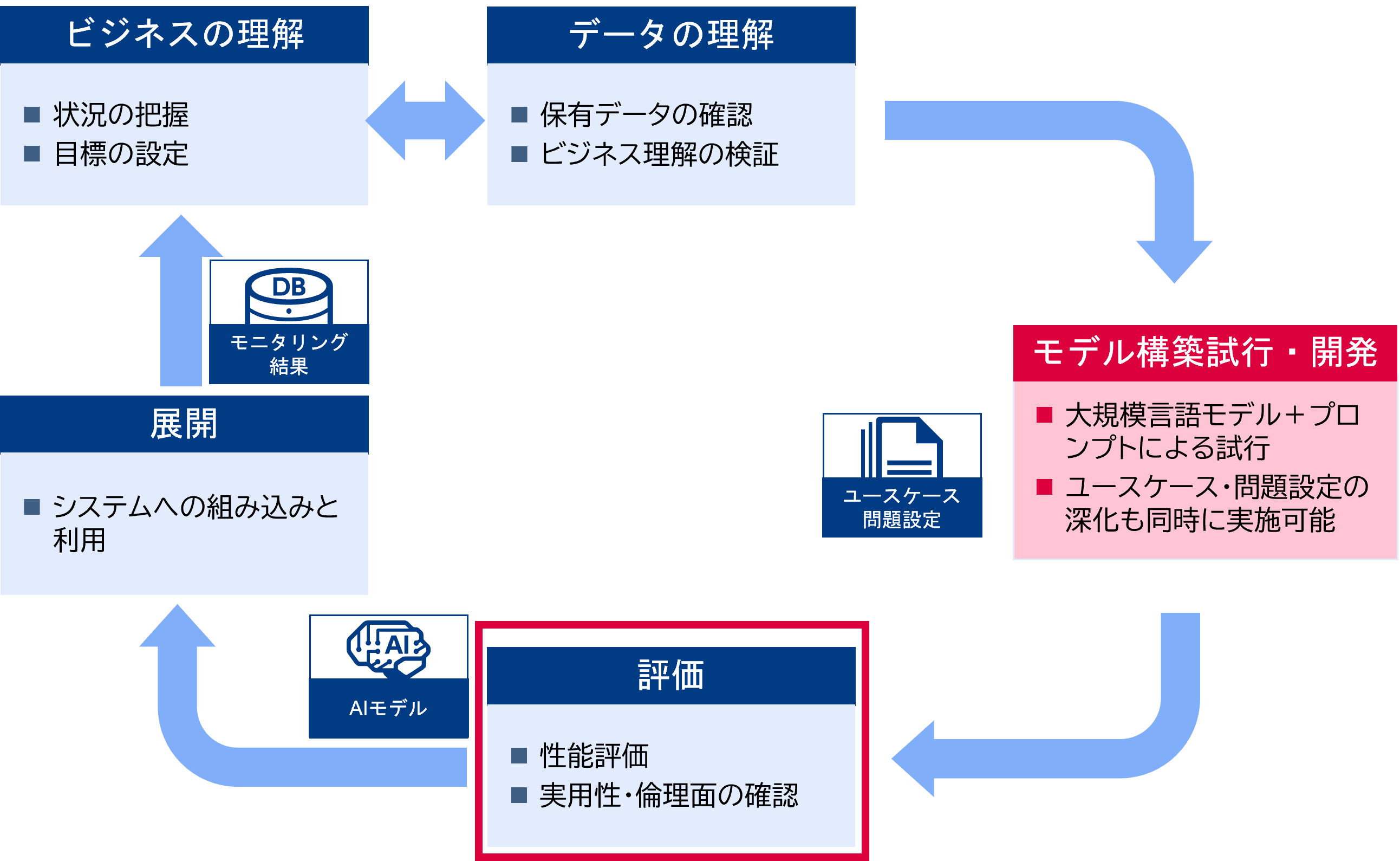
大規模言語モデルを使うと数例のデータで十分な性能が達成でき、大規模データ準備やモデリングが不要。モデル構築試行の中でユースケースや問題設定を深堀することが可能となった。
https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining
出所:三菱総合研究所
一方で評価の重要性は変わっていない。正しい評価ができていない場合、モデルのチューニングやプロンプトの工夫を行ってもそれが良い変化をもたらしているか判断できない。
評価の設計はユースケースや問題設定に依存する。何をもって「正しい」または「良い」とするか選択する事は簡単ではない。特に自然言語では曖昧性を排除できず人間であっても正しく判断できないことが多い。一般的に下記のようなステップで検討を進めていく。下記3.までの検討はユースケース検討時に実施する事が望ましい。
- ユースケース・問題設定に沿って評価項目と評価指標、目標値を設定する。評価項目はモデル性能(分類の正確さや回答の一致度)だけでなく、ノイズに対する耐性など複数設定する。評価項目ごとに適切な評価指標を選択し目標を決める。
- 評価項目に沿ったテストデータを作成する。ユースケースに沿った現実的なデータに加えノイズが入ったデータなどエッジケースに相当するものも作成する。
- テストデータを人間でラベル付けし正解データを作成する。正解データ作成時には複数人によるチェックを行い、人の間違いがどの程度あるかも記録する。人であっても目標が達成困難な場合はユースケースを見直す。
- 評価用のプログラムを作成し実行する。1.で設定した評価項目ごとにスコアを出し目標値と比較する。また、現実的な状況とノイズのある状況との性能差異や人との性能差異などを様々な軸でスコアを比較する。
問題によってはGPT-4など高性能なモデルを用いた自動評価も有益である。大規模言語モデルの活用や高速なfine tuning手法の登場によってモデルのチューニングサイクルが短くなり評価部分がボトルネックになりつつある。AIの性能評価には依然として様々なノウハウが必要であるが、可能な限り自動化を進めることが望ましい。
次回以降の予定
冒頭述べたように自然言語処理分野でAPIを通した大規模言語モデルの利用が増加している。一方でビジネスとして運用していく場合には性能やコスト面でオープンなモデルを用いることが良い場合も多い。オープンな大規模言語モデルの開発も進んでおり状況は流動的である。
以降のコラムでも大規模言語モデルの情報を適時アップデートしながらオープンなモデルのビジネス活用について紹介していきたい。
- 分類や質問応答タスクを生成系タスクとして解くことも可能であるなど厳密な区分けは難しい。
- Gradient Boosting Machine、XGBoostやLightGBMが有名
- Long Short Term Memory、大規模事前学習を行うTransformer以前に良く用いられていた手法
筆者



DXメルマガ
配信中

関連サービス・
ソリューション



プロダクト
マネージャー募集中
