
2022.11.24
高橋 怜士
最近のAI動向とオープン化
最近SNSで画像生成AIの話題が盛んに取り上げられている。画像生成AIは、テキストと画像という2種類のデータを扱う難しい取組であり、GoogleやOpenAI、Baiduなど各国の企業や研究機関が活発に研究している。近年、新たな手法の登場やデータの大規模化により生成される画像の品質が向上している。有償でのサービス展開を模索する企業が現れる中、無償かつ商用利用可能な条件でAIモデル「Stable Diffusion」が公開されたことは大きな話題となった。以下はStable Diffusionで筆者が作成した画像である。一見してAIが書いたとは思えない品質で作成することができた。


出所:Stable Diffusionによって筆者作成
Stable Diffusion以外にも数多くのAIモデルが、インターネット上で公開されている。分野も多岐にわたっており音声認識やOCRといった商用ソフトウェアが多い領域のAIモデルも公開され、そのまま利用できる。公開された学習済みモデルに手元のデータを追加で学習させて自社業務に特化したAIモデルを構築することも広く行われている。 ビジネスでのAI活用が増加していることもあり、既にオープンなモデルを実業務で利用する流れは広がっている。AI構築のためのソフトウェアやデータは大規模化しており自社のみでのAIモデル開発は難しくなっている。オープンなモデルを活用する流れは加速すると考えられる。 次章以降、オープンなAIとは何かという事と、オープンなモデルを利用する場合の一般的な注意点を解説する。第2回以降では領域(自然言語、画像処理など)に特化してビジネスでの活用方法を紹介していく。
オープンなモデルとは
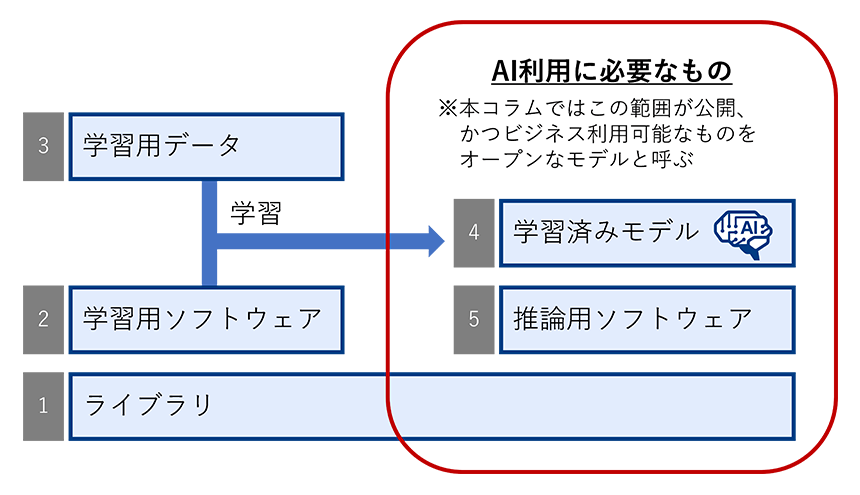
オープンなAIを考えるにあたり、AIの要素を「①ライブラリ」「②学習用ソフトウェア」「③学習用データ」「④学習済みモデル」「⑤推論用ソフトウェア」に分けて整理したい。
出所:三菱総合研究所
- ① ライブラリAI構築の基盤となるソフトウェアで基本要素を提供するものをライブラリと呼ぶ。ライブラリはオープンソースソフトウェアライセンスで公開されることが多い。有名なライブラリにはTensorFlow(Apache License 2.0)、PyTorch(修正BSDライセンス)、PaddlePaddle(Apache-2.0 license)がある。
- ② 学習用ソフトウェアAIモデルの定義(ネットワーク構造)、学習用の関数やパラメータ、データを読み込むプログラムを組み合わせたもの。学習用ソフトウェアに学習用データを入力することで学習済みモデルが作成される。多くの場合は①ライブラリを用いて作成されるソフトウェアである。ライブラリとは異なるライセンスを採用している場合もある。
- ③ 学習用データ学習用ソフトウェアに入力するためのデータ。ライセンスは様々でオープンソースソフトウェアのライセンスを採用しているもののほか、Creative Commons ライセンスを採用しているものもある。
- ④ 学習済みモデル学習用ソフトウェアに学習用データを入力し作成されたデータ、ネットワーク構造の重みを指す。本コラムではAIモデルと呼んでおり一般的に利用されるAIそのものである。学習済みモデルのライセンスは様々であり一般的なオープンソースソフトウェアの利用条件とは異なる記載が含まれる事がある。例えばStable Diffusionで採用されているCreativeML Open RAIL-M licenseには人に危害を与えるコンテンツの共有禁止に関する条項が入っている。
- ⑤ 推論用ソフトウェア学習済みモデルを実行するためのソフトウェア。AIモデルの定義(ネットワーク構造)のほか、AI実行に必要なパラメータ情報を含んでいる。②と同じソフトウェアである事も多い。
本コラムでは「オープンなモデル」を「①ライブラリ」「④学習済みモデル」「⑤推論用ソフトウェア」が公開され、かつ、ビジネスで利用可能なものと定義する。これは自由な再配布やソースコードの公開有無を重視する一般的なオープンソースソフトウェアの定義とは異なる事に注意していただきたい。
オープンなモデルは以下のようなサイトで共有されている。
前述のStable Diffusionの場合、ソースコードはGithubのリポジトリで公開され、学習済みモデルはHugging Faceで公開されている。
| カテゴリ | 概要 | ライセンス |
|---|---|---|
| ライブラリ | PyTorch Transformers など |
修正BSDライセンス Apache License 2.0 |
| 学習済みモデル | 開発者がHugging Faceで公開 | CreativeML Open RAIL-M |
| 推論用ソフトウェア | 開発者がGithubで公開 | CreativeML Open RAIL-M |
出所:三菱総合研究所
Stable Diffusionに関連するソフトウェアは簡単にインストールできる。学習済みモデルはユーザ登録後、利用規約に同意することでダウンロードできる。サンプルコードも付属しており試行は容易である。
オープンなモデルのビジネス利用の注意点
オープンなモデルをビジネス利用する際には大きく分けて「①ライセンスや知財に関する注意点」と「②利用用途・適用領域に関する注意点」の2つがある。前者は法的な側面が強く、後者は技術的な側面が強い。
- ① ライセンスや知財に関する注意点ソフトウェアやAIモデルを利用する場合は「①ライブラリ」「④学習済みモデル」「⑤推論用ソフトウェア」のライセンスと利用条件を守る必要がある。
近年のソフトウェアは多数のライブラリを使用しており開発者が全てを精査しているとは限らない点には注意が必要だ。特にビジネス利用では利用者側での確認が必須である。 - ② 利用用途・適用領域に関する注意点オープンなモデルは研究用途に公開され、特定条件のデータにのみ良い性能を発揮するなど利用用途や適用領域が限定されている事がある。例えば、ニュース記事はうまく翻訳できるが物語の翻訳性能は低い機械翻訳モデルも公開されている。
オープンなモデルの性能は保証されているものではなくサポートを受けることはできない。利用用途や適用領域で十分な性能を発揮するかは利用者側で検証する必要がある。
最近では公開された学習済みモデルにモデルカードが付与されている場合もある。モデルカードとはデータセットや学習過程、制約やバイアスについて整理、記載したものである(Stable Diffusionのモデルカード)。モデルカードはAI利用時に有用であるが、オープンなモデルの性能は保証されておらず、サポートを受けることもできない点は変わらない。利用用途や適用領域で十分な性能を発揮するかは、利用者側で検証しなくてはならない。
性能以外にもAI利用では頑健性や安全性、倫理性などの要素を考慮しなければならない(下図)。ソフトウェアライセンスやモデルカードなど開発者が提供する情報だけでは確認が難しく利用者側での十分なテストが必要になる。
性能以外にもAI利用では頑健性や安全性、倫理性などの要素を考慮しなければならない(下図)。ソフトウェアライセンスやモデルカードなど開発者が提供する情報だけでは確認が難しく利用者側での十分なテストが必要になる。
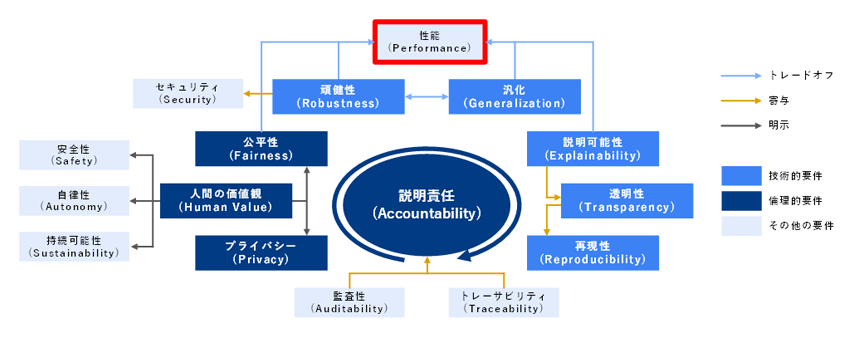
出所:「Li, Bo et al. "Trustworthy AI: From Principles to Practices." (2021).(CC-BY 4.0)」2022/6/14閲覧、論文中の図を元に三菱総合研究所作成
次回以降の予定
冒頭述べたようにモデルのオープン化が加速しているが、ライセンスの確認や検証など実ビジネスへの適用には留意すべき点は多く、弊社でも検証をしながらオープンなモデルの活用を進めている。以降のコラムでは利用用途(タスク)別に実例を交えながらオープンなモデルの現状とビジネスでの活用方法を紹介したい。
弊社でもこれらの活用を進めており、以降の回では実例を交えながらオープンなモデルの現状とビジネスでの活用方法を紹介したい。それぞれ利用用途(タスク)別の紹介とする予定である。
- 第1回: イントロダクション【本コラム】
- 第2回: 自然言語処理(タスク: 分類、質問応答)
- 第3回: 自然言語処理(タスク: クラスタリング、意味検索)
- 第4回: 自然言語処理(タスク: 要約、文章生成)
- 第5回: 画像処理(タスク: 物体検出・セグメンテーション)
- 第6回: 画像処理(タスク: 画像生成)
- 第7回: テーブルデータを対象とした処理(タスク: 表データを使った予測)
- 第8回: テーブルデータを対象とした処理(タスク: 時系列処理)
筆者


DXメルマガ
配信中

関連サービス・
ソリューション



プロダクト
マネージャー募集中
