
文章生成は、自然言語処理分野において広く研究されるテーマであり、GPT-4のような大規模言語モデル(LLM)に代表されるように、注目が集まっている。本稿では、主にLLMを中心として、文章生成にまつわる技術動向や実務適用に向けたオープンライブラリ・モデルの活用について紹介する。また、文章生成のタスクの一つである要約に焦点を絞り、LLMがもたらした技術的進歩を覗いていく。
文章生成の歩み
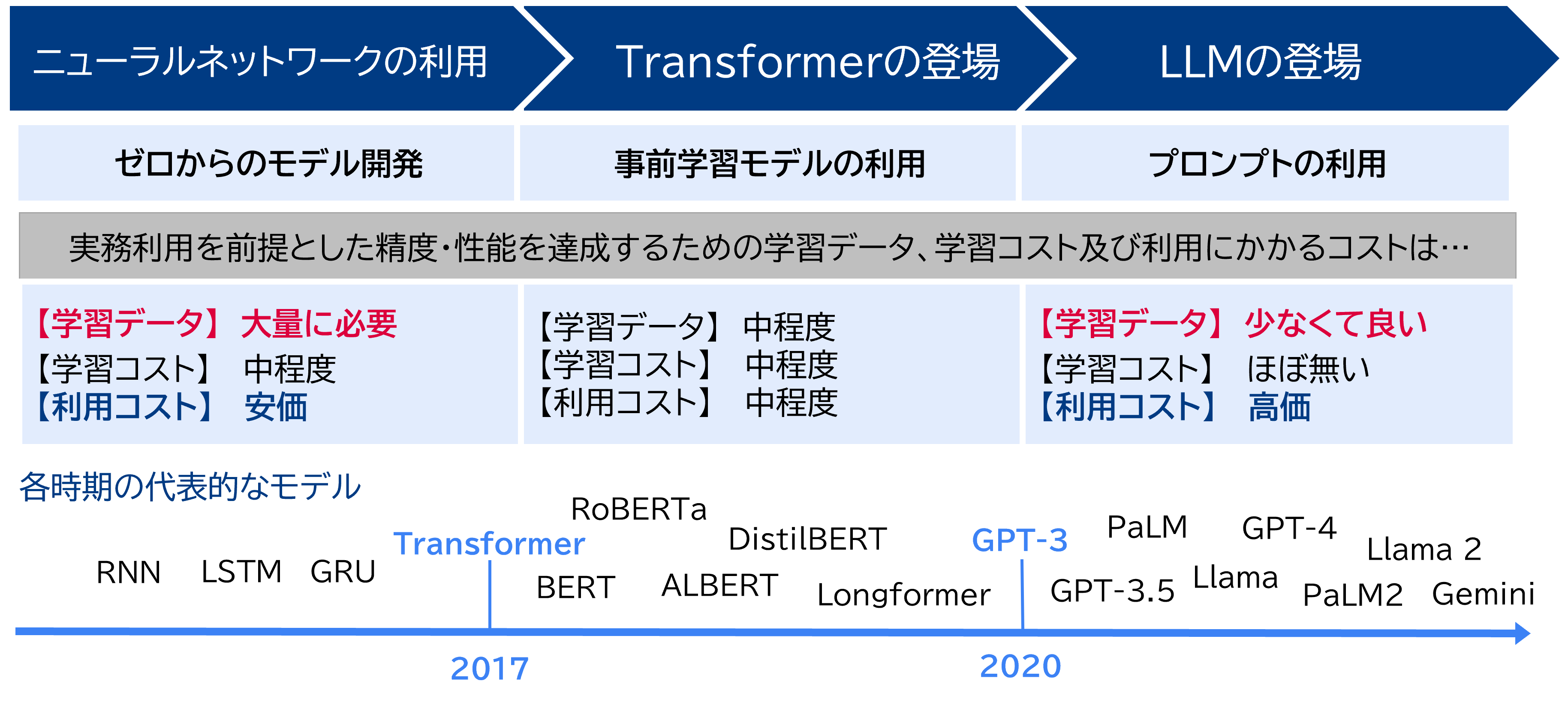
文章生成の根幹は、単語の確率分布に基づいて文の構造や意味をモデル化する、言語モデルである。言語モデルの歴史は古く、20世紀中期に提案されたN-gramから始まり 、今日では深層学習に基づくLLMに至るまで、顕著な進化を遂げている。機械学習やAIが言語モデルへ適用されるようになった、直近の技術の変遷を見ていくと、アプローチの違いの観点で大きく3つの時期に分解される。
出所:三菱総合研究所
- ① ニューラルネットワークモデルの利用 2017年頃までニューラルネットワークを用いたテキスト生成は、回帰型ニューラルネットワーク(RNN) や長・短期記憶(LSTM)ネットワークなどを用いて行われていた。RNNやLSTMは系列データの扱いに優れており、文章のように前後の文脈が重要になるデータに適している。一方で、文章が長くなると、単語間の意味的関係の学習が難しくなり、文脈を捉えきれなくなるという課題を抱えていた。
- ② Transformerの登場 ~事前学習モデルの利用 RNNやLSTMの課題を解決するアプローチとして、Transformerというアーキテクチャが登場した。Transformerは、Self-attention(自己注意機構)を利用して、文章内の離れた単語同士の意味的関係も学習できるようになった。また、Transformerの登場と同時に、Self-supervised Learning(自己教師あり学習)とファインチューニングの2段階で言語モデルを学習させるアプローチが流行した。自己教師あり学習とは、人間がアノテーションを行うことなく、機械的に生成された教師データで学習する手法である。自己教師あり学習とファインチューニングのそれぞれの役割として、まず自己教師あり学習により、大量のコーパスで文法や単語の意味等の一般的な概念を事前に学習させ、その後のファインチューニングにより、比較的少量のアノテーション付きコーパスで目的のタスクを学習させる。前段で得られるモデルを事前学習モデルと呼び、AI開発者は、公開された事前学習モデルを活用することで、ファインチューニングに注力できるようになった。
- ③ LLMの登場 ~学習データからの脱却・プロンプトの利用 2020年にGPT-3で注目されたフロンプトによって問題を解く方針は、 LLM全盛の現在、技術潮流の中心になっている。プロンプトとは、特定のタスクを実行させるための指示や質問を記した、言語モデルへの入力テキストである。指示となるプロンプトをモデルにそのまま入力(Zero-shot)、もしくはいくつかの回答の例示とともに入力(Few-shot)することで、LLMが持つ高い汎用性により、与えられた入力のコンテキストのみに基づいてモデルがタスクを理解し、高精度な回答を生成できることが研究で示されている 。パラメータ更新のための計算処理や学習データの用意が不要という点では、従来のファインチューニングと比較して、学習に掛かる開発コストが大幅に低減された。一方で、LLMは一般的に有償APIを通じて利用するため、その分の費用が掛かることに留意されたい。Zero/Few-shotのアイディアを発展させ、タスクの理解や回答の精度を向上させるためにプロンプトをどう設計すべきか、様々な手法が研究されている。
文章生成の代表的なタスク
文章生成の代表的なタスクを紹介する。LLMが登場する以前からの従来タスクとして、分類、要約、校正、翻訳等があげられる。これらのタスクの共通点として、アウトプットのオリジナリティは人間のアイディアであり、AIの役割はそれの変換や補完に留まることである。しかし、LLMが登場して以降は、その卓越した知識量と高度な文脈理解により、壁打ちやアイディア創出、コード生成等、オリジナリティを持ったアウトプットを伴うタスクや、自律的なタスクも可能となった。さらに、従来タスクもLLMを応用することで精度が向上していることが報告されている。
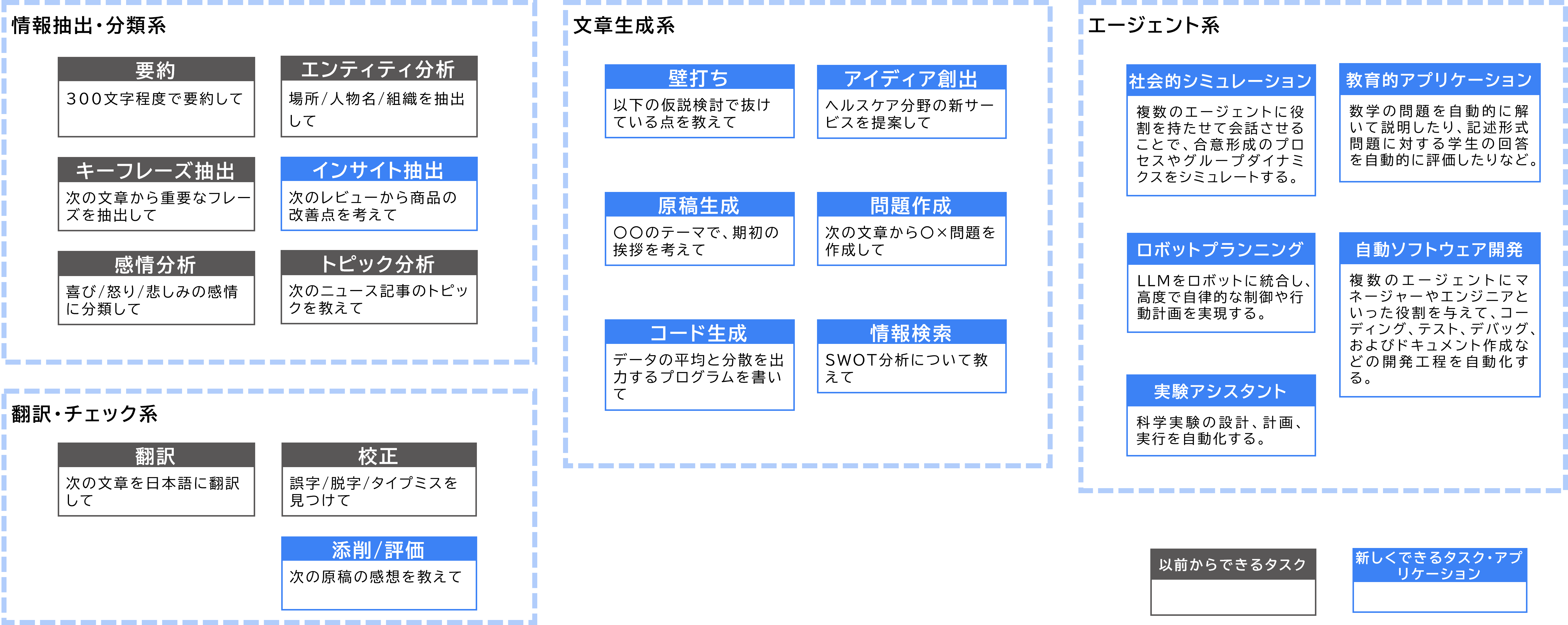
※エージェント系アプリケーションは、LLM単体で可能とするものではなく、アクションやプランニング等の自律動作用のモジュールを兼ね備えたアーキテクチャによって実現される。
出所:「ふくしまプログラミング推進協会_生成AIの使いこなし202311.pdf」「A Survey on Large Language Model based Autonomous」(2024/4/17 閲覧)の内容を元に三菱総合研究所作成
以降の内容は主に2点、1つ目は、要約タスクを例に、LLMによる従来タスクの精度向上の詳細について、2つ目は、LLMの更なる性能を引き出すための発展的な技術であるRAGについて紹介する。
要約タスクとLLM
文章生成タスクの一つである要約は、議事録や調査業務等、実務への適用可能性が高い。この章では、従来技術を振り返りながら、LLM登場以降の要約分野の動向について紹介する。 要約の従来からのアプローチとして、元のテキストから重要な文やフレーズを抽出し、それらを組み合わせて要約を作成するExtractive Summarizationや、言語モデル等により元のテキストを変化させる形で要約を生成するAbstractive Summarizationがあげられる。さらに、同じ記事であってもユーザーによって必要とされる情報は異なることがあるため、一般的な要約を超えて、目的に応じて様々な要約の形が取られる。例えば、キーワードに重点を置いた要約(Keyword-focused Summarization)、特定のクエリに基づく要約(Query-focused Summarization)、特定のトピックに基づく要約(Aspect-focused Summarization)等があげられる。
要約分野でも、文章生成の進展に倣い、ドメイン特化のデータで学習させたモデル(特化モデル)から、LLMを用いたZero/Few-shotのアプローチへとパラダイムシフトしつつある。近年の研究で、要約用データセットでファインチューニングした従来のモデルよりも、プロンプトのみで指示されたGPT-3(text-davinci-002)による要約の方が、人間の好みに基づく比較実験において遥かに優れていることが示された 。
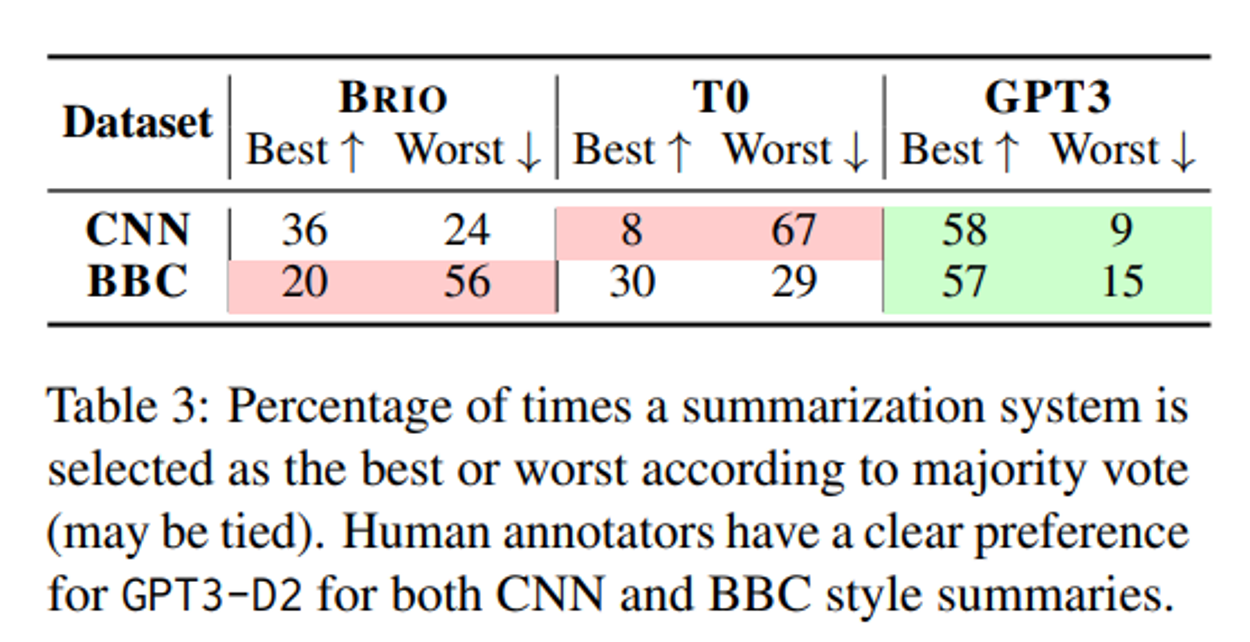
※ T0はGPT3よりも小規模なLLM
※ 実験方法としては、60名のモニター参加者に3モデルの要約結果を見せ、最良の要約(Best)と最低の要約(Worst)を選ばせる。引き分けも許容する。データセットは、CNNとBBCの2種類のニュースデータセットを使用
出所:「News Summarization and Evaluation in the Era of GPT-3」(2024/4/1 閲覧)
原著では、この実験結果を踏まえ、従来のドメイン特化型の学習における潜在的な問題点を指摘している。要約タスクで使用される代表的なデータセットCNNは、ニュース記事をスクレイピングし、それらを既存の要約データと組み合わせて構築される。ここでの要約データは、ニュース記事に付随する箇条書きのサマリである。このような方式は、アノテーションデータを効率的に提供する一方で、その品質や人間の好みとの一致が重視されていない可能性を本実験結果が示唆している。したがって、そのような(意図して設計されていない)付随的なアノテーションでファインチューニングしたモデルは実用に供さない可能性がある、と述べられている。
最後に、LLMで要約を行う際の、典型的なプロンプトテクニックを紹介する。
- サイズの制御
「この記事をN文で要約してください」といったプロンプトを与えることで、要約後の文章のサイズを制御する。なお、「N文字で要約してください」といったような、文字数の細かな指定は、経験上あまり上手くいかない。
- キーワードの制御
「この記事を要約してください。キーワードとして、”大規模言語モデル”に注目してください」といった形式で、要約で主眼とするキーワードを指定する。Keyword-focused Summarizationに相当する。
- アスペクトの制御
「この記事を要約してください。筆者の主張に注目してください」といった形式で、要約の観点や目的を指定する。Query-focused SummarizationやAspect-focused Summarizationに相当する。
これらのプロンプトは、基本的な役割を果たす最小限の例である。要約の目的に応じて、より具体的な指示を与えることで、更なる精度向上が期待される。例えば、論文等の専門的な文書を要約する場面では、「初学者でもわかるように、平易な言葉で要約してください」といったプロンプトも効果的かもしれない。
オープンライブラリによるRAG
LLMによる文章生成を、実務利用に向けて更に発展させるための重要技術を紹介する。翻訳や校正等の普遍的なタスクであれば、ChatGPTのように一般的な自然言語処理タスクに最適化されたLLMをそのまま使用するだけで十分なケースもあるが、より高度な実務利用では多くの場合、更なる性能を引き出すための工夫が必要である。そのような工夫の1つとして、Retrieval Augmented Generation (RAG)がある。RAGとは、外部データソースから取得した情報をプロンプトに加えることで、LLMの回答の精度と信頼性を向上させる技術である。
本章では、オープンライブラリを使用してRAGを実現する方法を紹介する。ここでは、データソースはドキュメントとして既に用意されている前提とする。したがって、目指すものとしては、社内文書等のプライベートデータに基づくRAGである。LlamaIndexは、そのようなRAGの実現に資するオープンライブラリの1つである。LlamaIndexでは、プロンプトに収まりきらない大規模なドキュメントを、どう取捨選択して効果的にLLMに読み込ませるかに焦点を当てている。そのアプローチは大まかに、ドキュメントを検索しやすいように構造化(インデックス化)し、ユーザーが入力したクエリに基づいてインデックスから関連する情報を取り出して回答を生成する、というものである。インデックスの作成方法にはいくつか種類があり、それぞれの原理と特徴を紹介していく。
- リストインデックス
まず、ドキュメントをノードと呼ばれる小さなフラグメント(チャンク)に分割する。分割の方法としては、例えば句読点や改行で区切った後、均等の長さになるように各ノードに格納していく等、いくつかの方法がある。そうしてできたノードを順次つなぎ合わせ、リストとして格納したものがリストインデックスである。
- ベクトルストアインデックス
ベクトルストアインデックスでは、リストインデックスと同様にノード分割した後、各ノードのベクトル表現をストアに格納する。ベクトル表現とは、大まかにはテキストの特徴を数値化したものである。そして、クエリのベクトルと各ノードのベクトルを照合して類似度を計算し、その数値が高い(関連性が高い)ノードを抽出して、回答を生成する。
- ツリーインデックス
ツリーインデックスも、ベクトルストアインデックスのように関連性の高いノードを抽出して回答するアプローチの1つである。ツリーインデックスでは、その名の通り、ツリー構造を用いてノードを格納する。ツリーの末端のノード(葉ノード)は、ドキュメントを分割して得られた各ノードに該当し、その親ノードは葉ノードを要約したテキストを保持する。クエリを受け取ると、根ノードから開始して、ベクトルの類似度等に基づいて関連性の高い子ノードを選択しながらトラバースしていき、最終的に到達した葉ノードのテキストに基づいて回答する。
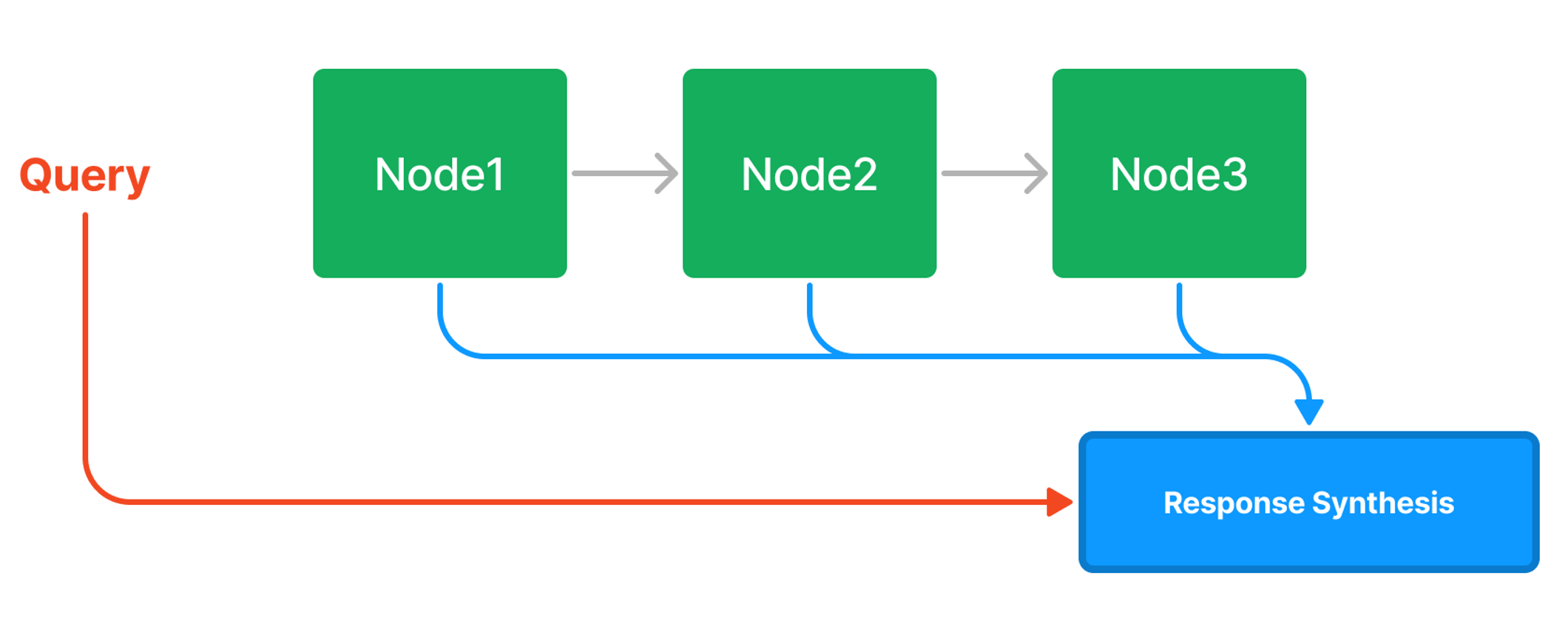
リストインデックスによる回答生成の方法は大まかに、リスト内の各ノードにクエリを投げ、その全ての回答を合成するというものである(デフォルトの場合)。なお、複数の回答を合成することを、LlamaIndexではResponse Synthesisと呼ぶ。回答の合成とは、具体的にどのように行うのか。いくつか方法があるが、ここではリファインと呼ばれる手法を紹介する。リファインでは、まず1つ目のノードのテキストをクエリとともにプロンプトに加えて、最初の回答を取得する。そして、以下のようなプロンプトテンプレートを使用して、2つ目のノードのテキストに基づいてその回答を改善する。この一連を最後のノードまで繰り返すことで最終的な回答を取得する。

以下は、イヌ科の生物について解説するドキュメントに基づいて、回答を生成する例である。リストインデックスを用いることで、「イヌ科の動物には、何がいますか?」というクエリに対して、各ノードに分散するイヌ科の動物の情報を統合して回答することが可能となる。
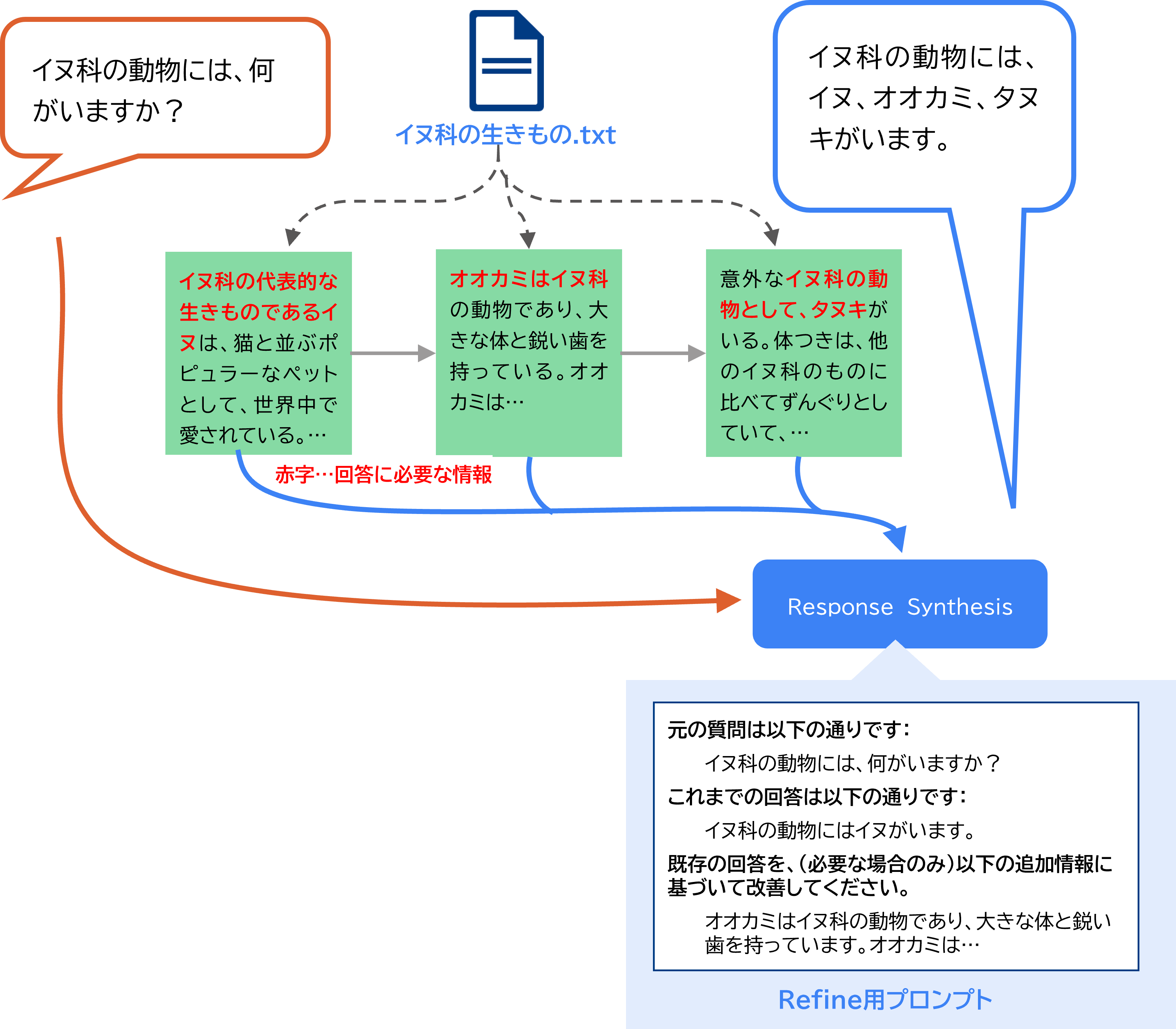
出所:三菱総合研究所
このように、リストインデックスではドキュメント全体の情報を網羅した回答が可能である。その反面、一つ一つのノードに対して回答を生成するため、最終的な回答の生成までに時間を要することやAPI利用料がかさむこと、また、全ての情報が同等に扱われるため、本来フォーカスすべき情報が埋もれてしまい、回答の主旨がずれる可能性があることがデメリットとして考えられる。
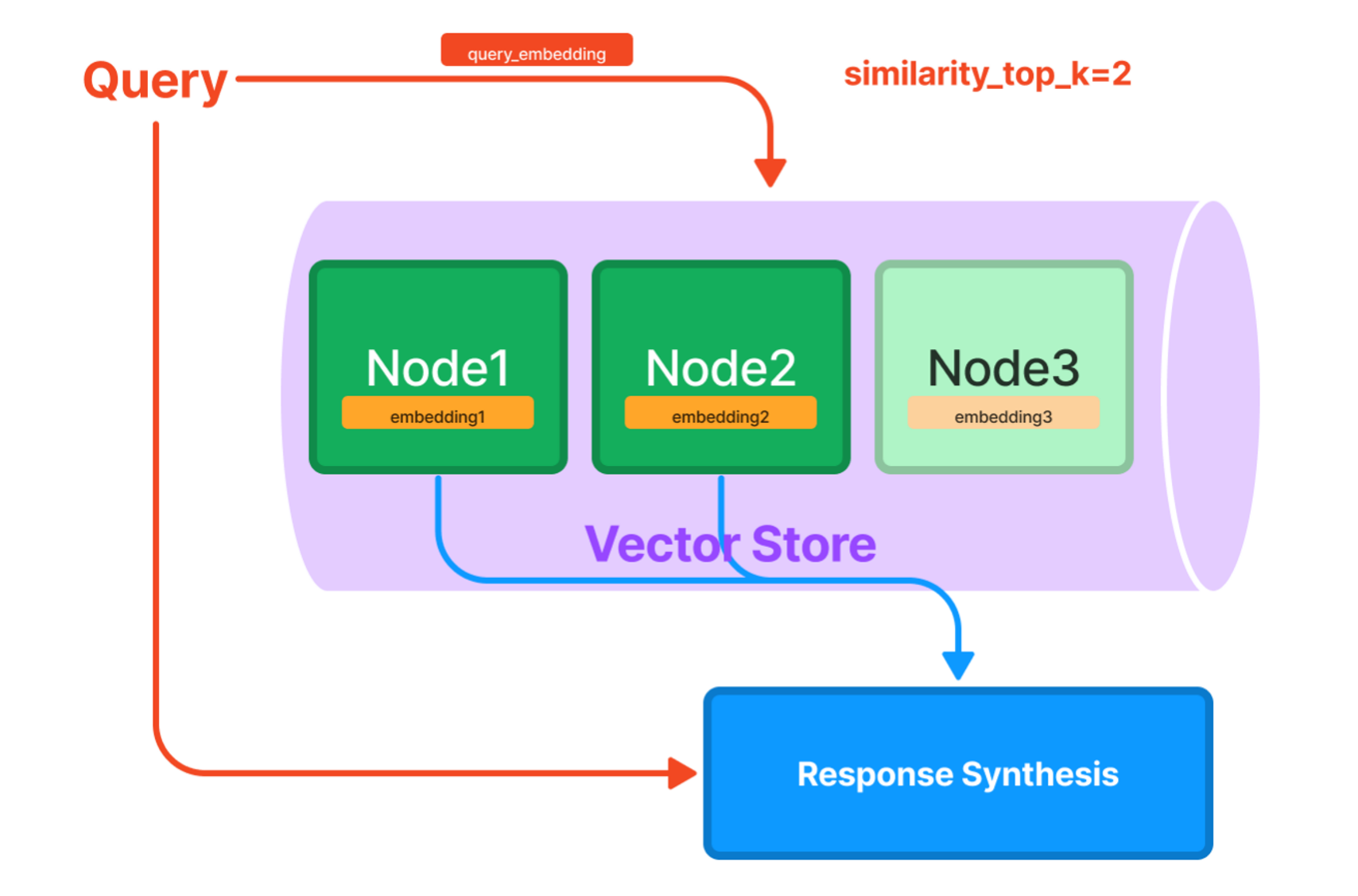
出所:「How Each Index Works - LlamaIndex 🦙 v0.10.15」(2024/4/1 閲覧)
以下は、「パンダの主食は何ですか?」というクエリに対して、ドキュメントを参照しながら回答を生成する例である。ベクトル検索を用いることで、「パンダは笹の葉やタケノコを食べる」という情報をピンポイントに抽出して回答が生成できる。
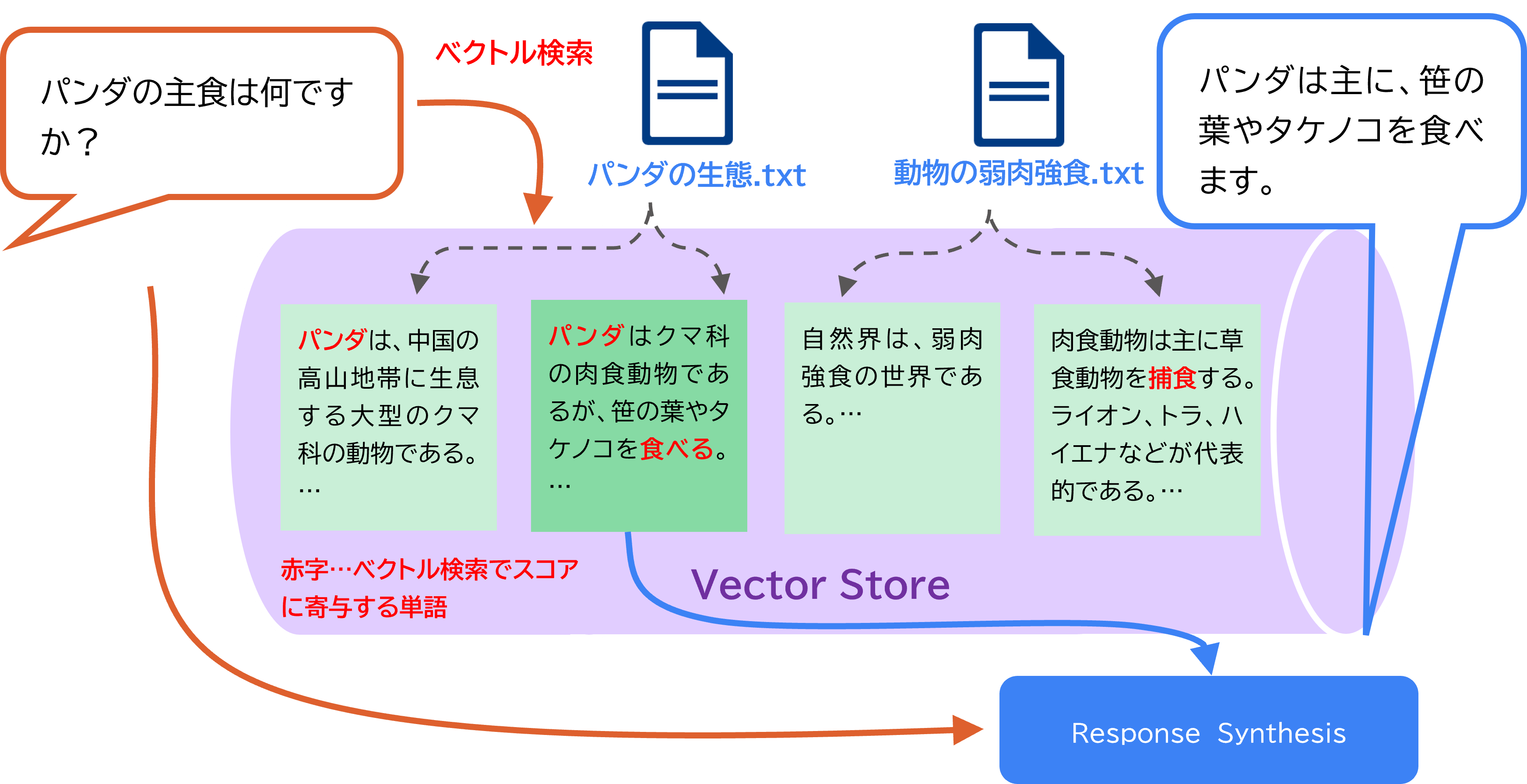
※この例では検索スコア1位のみを抽出しているが、上位複数を抽出するような設定も可能
出所:三菱総合研究所
回答生成のためのAPI通信は1回(オプションによっては複数回)で済む。一方で、特定のノードのみを情報源として使用するため、ドキュメント全体を網羅するような回答の生成には向かない。
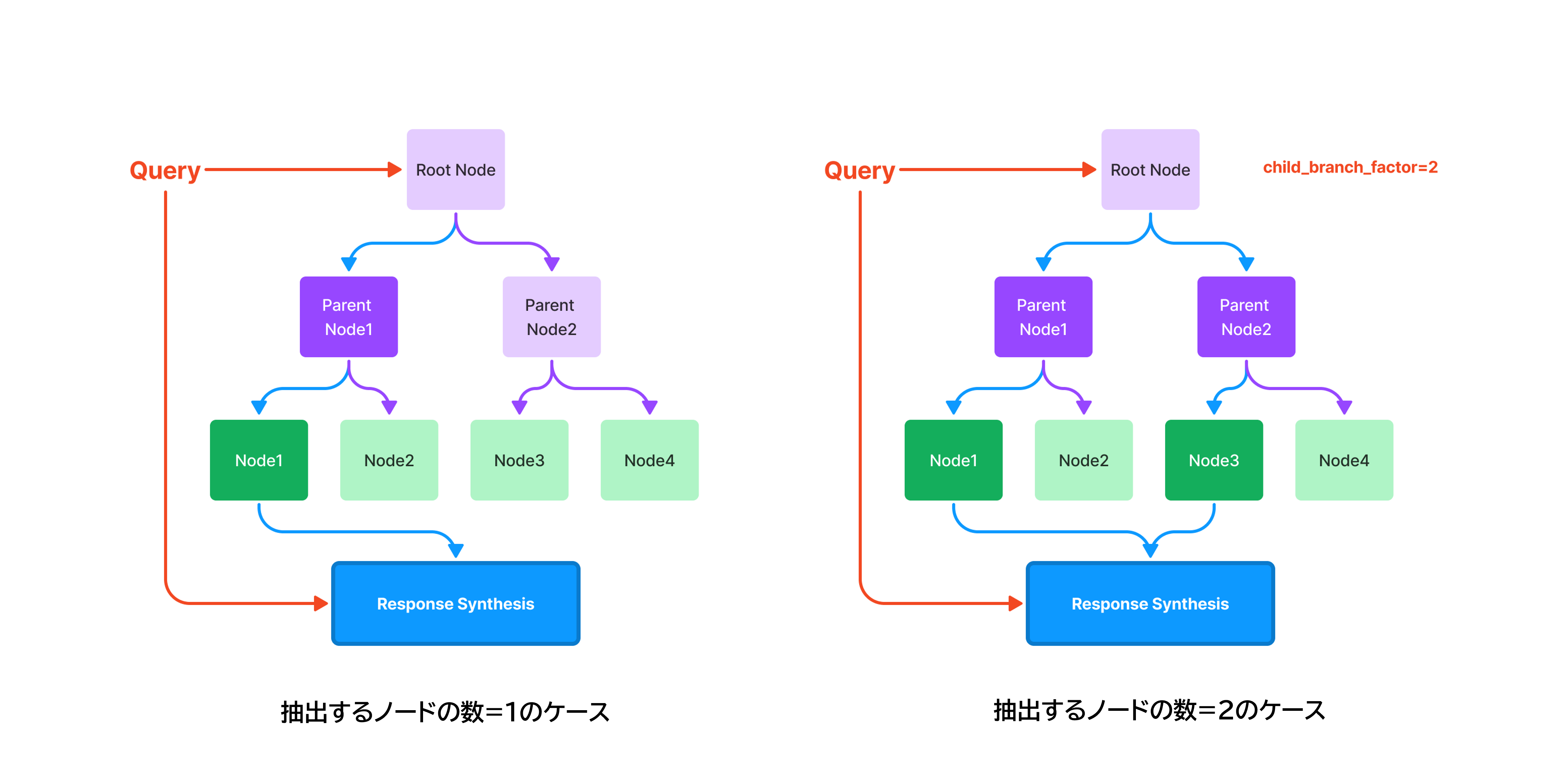
出所:「How Each Index Works - LlamaIndex 🦙 v0.10.15」(2024/4/1 閲覧)
補足のためのキャプションを三菱総合研究所加筆
以下は、「動物園のライオンは、何を食べますか?」というクエリに対して回答を生成する例である。野生動物に関するドキュメントと、動物園に関するドキュメントが併存するため、野生のライオンの話か、動物園のライオンの話かを区別する必要があるが、親ノードの要約から、動物園の話という文脈を読み取ることで適切に選択できている。
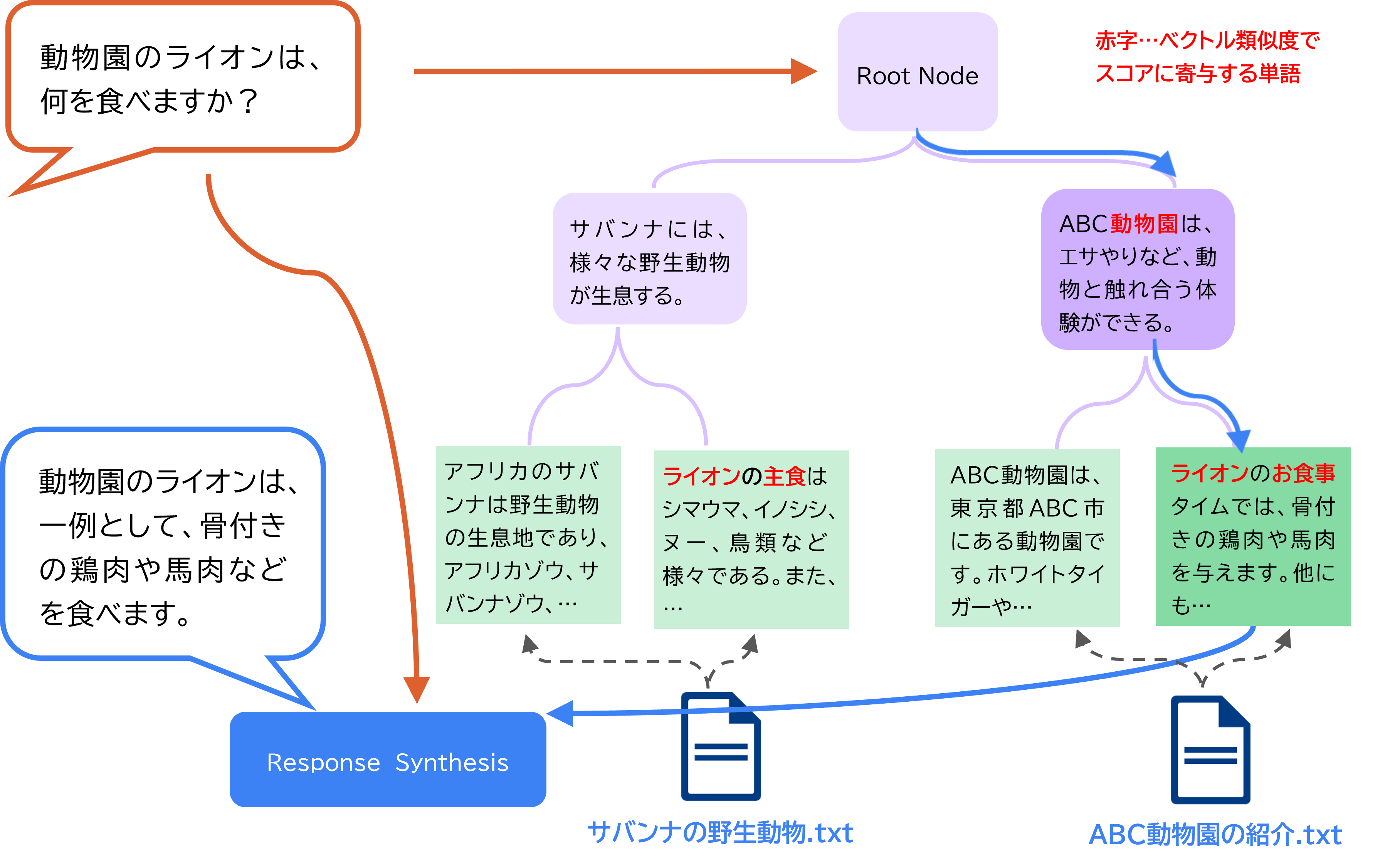
※ この例では抽出されるノードは1つのみであるが、複数ノードを抽出するような設定も可能
※ この例のように、常にドキュメントごとに完全に二分されるツリーが構築されるとは限らない。
出所:三菱総合研究所
留意点として、最初にツリーを構築する際に各ノードに対する要約処理が発生するため、その分オーバーヘッドが大きい。
以上のように、各インデックスに一長一短があるため、目的や制約に合わせた取捨選択が必要である。また、本稿で紹介したもの以外にもインデックスの種類はあるため、詳しくは公式ドキュメントを参照されたい。
終わりに、LLMのオープンモデルについて紹介する。ChatGPT等の商用LLMは、利用料が掛かることや、通信障害等による可用性の懸念、ユーザーの入力がモデルの学習に二次利用されるなどのセキュリティ上の懸念が考えられる。そのため、自社環境で動作できるオープンモデルのニーズは高い。また、ビジネスへの導入の容易さという点で、チャット用にファインチューニングされていることが望ましい。そのようなファインチューニングモデルのオプションを持つオープンモデルについて、一例を紹介する。
- Llama 2
- Meta社により開発。パラメータ数が70億、130億、700億と段階的に異なる3つのモデルを提供
- ライセンスは独自ライセンス(Llama 2 Community License)
- Llama 2 Community License Agreement - Meta AI
- 商用利用を可能とするが、月間アクティブユーザーが7億人以上の場合は、Meta社にライセンスを申請する必要あり
- ELYZA-japanese-Llama-2-13b
- 株式会社ELYZAにより開発。130億パラメータのLlama 2に対し、日本語テキストで追加事前学習を実施
- ライセンスはLlama 2に準拠(Llama 2 Community License)
- Mistral 7B
- Mistral AI社により開発。パラメータ数は70億
- ライセンスはApache-2.0
- Japanese StableLM Instruct Alpha 7B v2
- Stability AI Japan社により開発された日本語向けLLM。パラメータ数は70億
- ライセンスはApache-2.0
LLMのオープンモデルについては、第2回: 自然言語処理(タスク: 分類、質問応答)でも解説しているため、参照されたい。
まとめ
本稿では、要約タスクにおけるLLMの効用と、外部データとの連携によりLLMの更なる性能を引き出すための技術であるRAGについて紹介した。LLMを取り巻く技術動向は、今なお目まぐるしく変化し、日々新たな技術や知見が発表される。そのような膨大な情報の中から、正確な情報や目的に沿う情報を取捨選択するためには、LLMのこれまでの発展の系譜を理解することが重要である。その端緒として、本稿が手立てとなれば幸いである。
次回以降は、テキストデータと同様にビジネスにおけるデータ利活用で重要となる、画像とテーブルデータについて、重要技術を紹介していく。
- 「深層学習に基づく言語モデルと音声言語理解」(2024/4/2閲覧)
- RNN自体は古くから存在するニューラルネットワークであり、元々は言語モデルとして提案されたものではなく、2010年の論文「Recurrent Neural Network Based Language Model」(2024/4/1閲覧)により言語モデルへの応用が提案された。
- 「Language Models are Few-Shot Learners」「What Makes Good In-Context Examples for GPT-3?」「Large Language Models are Zero-Shot Reasoners」2024/4/1閲覧
- 「Chain-of-Thought Prompting Elicits Reasoning in Large Language Models」「Tree of thoughts: Deliberate problem solving with large language models」「SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models」「Large Language Models: A Survey」2024/4/1閲覧
- 「20230217_AIの進化と日本の戦略_松尾研」「ふくしまプログラミング推進協会_生成AIの使いこなし202311.pdf」「A Survey on Large Language Model based Autonomous」2024/4/17閲覧
- 要約タスクの精度向上については、本稿で紹介する。その他のタスクについては、※5の出典を参考
- 「News Summarization and Evaluation in the Era of GPT-3」2024/4/1閲覧
- 「Atlas: Few-shot Learning with Retrieval Augmented Language Models」「Improving language models by retrieving」「Augmented Language Models: a Survey」2024/4/1閲覧
- 「LlamaIndex - LlamaIndex」2024/4/1閲覧
- 「Modules - LlamaIndex」2024/4/1閲覧


DXメルマガ
配信中

関連サービス・
ソリューション



プロダクト
マネージャー募集中
